Source: https://opencitations.wordpress.com/2019/01/02/opencitations-enhancement-project-final-report/
The OpenCitations Enhancement Project
Report period: 1st May 2017 – 30 November 2018.
Report written: 30th December 2018
The Directors of OpenCitations are David Shotton, Oxford e-Research Centre, University of Oxford (david.shotton@opencitations.net), and Silvio Peroni, Digital Humanities Advanced Research Centre, Department of Classical Philology and Italian Studies, University of Bologna (silvio.peroni@opencitations.net). We are committed to open scholarship, open data, open access publication, and open source software. We espouse the FAIR data principles developed by Force11, of which David Shotton was a founding member (https://www.force11.org/group/fairgroup/fairprinciples), and the aim of the Initiative for OpenCitations (I4OC, https://i4oc.org), of which both David Shotton and Silvio Peroni were founding members, to promote the availability of citation data that is structured, separable, and open.
Ivan has been responsible for the development of new visualization and programming interfaces for exploring and making sense of the citation data included in the OCC and in the new OpenCitations Indexes, for the main part of the scripts related to the population and regular maintenance of COCI (The OpenCitations Index of Crossref open DOI-to-DOI citations, the first of the OpenCitations Indexes), and for conference presentations and paper writing.
We have together harmoniously developed the concept of and vision for OpenCitations as an infrastructure organization, the structure and content of the OpenCitations web site (http://opencitaitons.net), the classes and properties of our supporting SPAR ontologies (http://www.sparontologies.net), and the community of collaborators and users of our developments. This has involved outreach and dissemination at a number of international research conferences, involvement with publishers through the Initiative for Open Citations, and associated publications.
We have studied and preliminarily tested a new scalable architecture centred on one powerful independent physical server, that both stores and handles all the data in the Corpus and in the new OpenCitations Indexes, and also offers adequate performance for query services. This server is supplemented by 30 additional small physical machines, Raspberry Pi 3Bs, working in parallel, each in charge of ingesting a defined set of reference lists and feeding the ingested data to the central server for further processing and storage as RDF in our Blazegraph triplestore.
The first of these OpenCitations Indexes is COCI, the OpenCitations Index of Crossref open DOI-to-DOI citations, an RDF dataset containing details of all the citations that are specified by the open references to DOI-identified works present in Crossref, as of the latest COCI update. COCI does not index Crossref references that are closed, nor Crossref references to entities that lack DOIs. These citations are treated as first-class data entities, with accompanying properties including the citations timespan and possible kinds of self-citation characteristics, modelled according to the index data model described in the OpenCitations Indexes page. COCI was launched in July 2018, and the most recent update of COCI is dated 12 November 2018. It presently contains 449,840,503 citations between 46,534,705 bibliographic resources. COCI is the first citation index released by OpenCitations, being a bibliographic index recording citations between publications that permits the user to establish which later documents cite earlier documents, and to create citation graphs of these citations.).
While full coverage of the scholarly citation graph depicted by the aforementioned datasets (or as full as practically possible) is required for the calculation of certain bibliometric indicators such as journal impact factors and individual h-indexes (Hirsch numbers), partial coverage while OCC grows is still of value, since it includes citations of all the most important biomedical papers obtained from the Open Access Subset off PubMed Central. These can be easily recognized by their large number of inward citation links, and can be used to explore the development of disciplines and research trends. In addition, COCI, with its wider scope, has sufficient coverage to be used for large-scale bibliometrics analysis.
In addition, we have completed the transition of all the OpenCitations software from the old GitHub repository (i.e. https://github.com/essepuntato/opencitations) to a new GitHub organization, namely https://github.com/opencitations. This organisation includes several repositories which permit third parties to initiate the whole suite of OpenCitations software on a local machine. This is of key importance for the resilience of this open source project.
Initially, the goal we had was to develop ad-hoc user interfaces to abstract the complexities of the SPARQL endpoints into well-designed Web interfaces that anyone could use. During the development, though, we thought it would be better to develop generic frameworks for building customizable interfaces that allow one to expose, in a more human-understandable way, RDF data stored in any RDF triplestore and accessible through any SPARQL-endpoint, so as to forster reuse of such software in contexts that, in principle, might go far beyond the OpenCitations domain.
To this end we developed three different open software applications:
All these applications have been used to produce several interfaces to all the datasets released by OpenCitations. In particular, we have created user-friendly textual search interfaces (via OSCAR) both for the OCC (see the search box now on the OpenCitations home page, and the related search page) and for COCI (see the related search page). We have additionally developed browsing applications (via LUCINDA) to permit humans an easier navigation of all the entities included in the OCC (e.g. see the bibliographic resource br/1791056) and in COCI (e.g. see the citation oci:02001010806360107050663080702026306630509-02001010806360107050663080702026305630301). Finally, we have also implemented REST HTTP APIs (via RAMOSE) for simplifying the queries to both datasets, the OCC and COCI, by Web developers with no expertise in Semantic Web technologies.
In addition, in order to demonstrate its flexibility, we have also created two web pages using OSCAR, LUCINDA, and RAMOSE for permitting similar tasks (text query, browsing, and REST APIs) on the scholarly data in Wikidata / WikiCite – another project recently funded by the Alfred P. Sloan Foundation. These interfaces have been introduced in two distinct event: during the hack day of the Workshop on Open Citations 2018 and during the WikiCite 2018 Conference.
A further prototypical interface / service has been recently proposed so as to try to gather additional open citation data to include in the OCC, involving users of the scholarly domain such as editors and researchers. This application is called BCite [Daquino et al., 2018]. BCite is designed to provide a full workflow for citation discovery, allowing users to specify the references as provided by the authors of an article, to retrieve them in the required format and style, to double-check their correctness, and, finally, to create new open citation data according to the OpenCitations Data Model [Peroni and Shotton, 2018d], so as to permit their future integration into the OCC. While presently only a prototype, we received several commendations for this tool, and we are currently studying funding strategies to develop a full standalone application that can be used by anyone and that allows users to directly interact with the OCC, so as to upload new data into the Corpus.

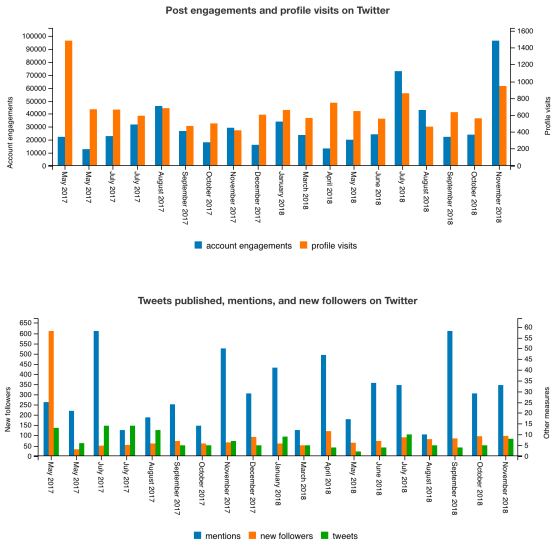
 In the past nineteen months, the posts published by the official
Twitter account of OpenCitations have been engaged by 599,200 distinct
Twitter accounts, the Twitter profile (@opencitations)
has been visited 12,719 times and has been mentioned in 565 tweets
written by others, and it has collected an additional 1,925 followers.
The diagram below shows all these statistics month by month.
In the past nineteen months, the posts published by the official
Twitter account of OpenCitations have been engaged by 599,200 distinct
Twitter accounts, the Twitter profile (@opencitations)
has been visited 12,719 times and has been mentioned in 565 tweets
written by others, and it has collected an additional 1,925 followers.
The diagram below shows all these statistics month by month.
 Although we made relatively few new blog posts in the reporting
period (there have been twenty more since then), from May to November
2018, the blog dedicated to OpenCitations (https://opencitations.wordpress.com)
received 19,454 visits by 15,184 distinct users. As shown in the
diagram below, the biggest peaks in terms of visits has been in July
2018 (the month when we launched COCI) and in September 2018 (the month
of the Workshop on Open Citations).
Although we made relatively few new blog posts in the reporting
period (there have been twenty more since then), from May to November
2018, the blog dedicated to OpenCitations (https://opencitations.wordpress.com)
received 19,454 visits by 15,184 distinct users. As shown in the
diagram below, the biggest peaks in terms of visits has been in July
2018 (the month when we launched COCI) and in September 2018 (the month
of the Workshop on Open Citations).

To date, as far as we are aware, more than 677 papers have been published that cite or use one or more of the SPAR ontologies. For the full list, see http://www.sparontologies.net/uptake#publications.
Because open reference lists are necessary for the population of OCC, we at OpenCitations have devoted considerable effort to promoting I4OC’s aims, and we host the I4OC web site on behalf of that community.
Within a short space of time, I4OC has persuaded most of the major scholarly publishers to open their reference lists submitted to Crossref, so that the proportion of all references submitted to Crossref that are now open has risen from 1% to over 50%. These are now available for OpenCitations to harvest into the OpenCitations Corpus and publish in RDF, as well as for others to harvest and use as they wish [Shotton, 2018].
Ivan Heibi, Silvio Peroni, David Shotton (2018). Enabling text search on SPARQL-endpoints through OSCAR. Submitted for publication to Data Science – Methods, Infrastructure, and Applications. OA at at https://w3id.org/people/essepuntato/papers/oscar-datascience2019/
Ivan Heibi, Silvio Peroni, David Shotton (2018). OSCAR: A Customisable Tool for Free-Text Search over SPARQL Endpoints. In Semantics, Analytics, Visualization – 3rd International Workshop, SAVE-SD 2017, and 4th International Workshop, SAVE-SD 2018, Revised Selected Papers: 121-137. DOI: https://doi.org/10.1007/978-3-030-01379-0_9, OA at https://w3id.org/people/essepuntato/papers/oscar-savesd2018.html
Silvio Peroni, David Shotton (2018). OpenCitations: enabling the FAIR use of open citation data. In Proceedings of the GARR Conference 2017 – The data way to Science – Selected Papers. DOI: https://doi.org/10.26314/GARR-Conf17-proceedings-19
Silvio Peroni, David Shotton (2018). The SPAR Ontologies. In Proceedings of the 17th International Semantic Web Conference (ISWC 2018): 119-136. DOI: https://doi.org/10.1007/978-3-030-00668-6_8
Silvio Peroni, David Shotton, Fabio Vitali (2017). One year of the OpenCitations Corpus: Releasing RDF-based scholarly citation data into the Public Domain. In Proceedings of the 16th International Semantic Web Conference (ISWC 2017): 184-192. DOI: https://doi.org/10.1007/978-3-319-68204-4_19, OA at https://w3id.org/people/essepuntato/papers/oc-iswc2017.html
David Shotton (2018). Funders should mandate open citations. Nature 553: 129. https://doi.org/10.1038/d41586-018-00104-7
Silvio Peroni, David Shotton (2018). Open Citation Identifier: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.7127816.v1
Silvio Peroni, David Shotton (2018). The OpenCitations Data Model. Figshare. DOI: https://doi.org/10.6084/m9.figshare.3443876.v5
15 May 2017: The Sloan Foundation funds OpenCitations
24 Nov 2017: Milestone for I4OC – open references at Crossref exceed 50%
24 Nov 2017: Elsevier references dominate those that are not open at Crossref
28 Nov 2017: Openness of non-Elsevier references
9 Jan 2018: The new Crossref reference distribution policy
9 Jan 2018: Barriers to comprehensive reference availability
15 Jan 2018: Funders should mandate open citations
16 Jan 2018: Oxford University Press opens its references!
29 Jan 2018: OpenCitations and the Initiative for Open Citations: A Clarification
19 Feb 2018: Citations as First-Class Data Entities: Introduction
22 Feb 2018: Citations as First-Class Data Entities: Citation Descriptions
25 Feb 2018: Citations as First-Class Data Entities: The OpenCitations Data Model
4 Mar 2018: Citations as First-Class Data Entities: The OpenCitations Corpus
12 Mar 2018: Citations as First-Class Data Entities: Open Citation Identifiers
15 Mar 2018: Citations as First-Class Data Entities: The Open Citation Identifier Resolution Service
23 Mar 2018: Early adopters of the OpenCitations Data Model
17 Apr 2018: Workshop on Open Citations
12 Jul 2018: COCI, the OpenCitations Index of Crossref open DOI-to-DOI references
19 Nov 2018: New release of COCI: 450M DOI-to-DOI citation links now available
A further Workshop on Open Citations is being planned for autumn 2019.
WikiCite Conference 2017, Vienna, 23 May 2017, https://www.slideshare.net/essepuntato/opencitations (Silvio Peroni and David Shotton)
COASP 9, 9th Conference of Open Access Scholarly Publishing, Lisbon, 20 September 2017, https://www.slideshare.net/essepuntato/the-initiative-for-open-citations-and-the-opencitations-corpus (David Shotton)
SemSci 2017, 1st International Workshop on Enabling Open Semantic Science, Vienna, 21 October 2017, https://w3id.org/people/essepuntato/presentations/the-open-citations-revolution.html (Silvio Peroni)
ISWC 2017, 16th International Semantic Web Conference, Vienna, 24 October 2017, https://w3id.org/people/essepuntato/presentations/oc-iswc2017.html (Silvio Peroni)
FORCE 2017, Research Communication and e-Scholarship Conference, Berlin, 27 October 2017, http://w3id.org/people/essepuntato/presentations/oc-force2017.html (Silvio Peroni)
Linked Open Citation Database (LOC-DB) Workshop, Mannheim, 7 November 2017, https://locdb.bib.uni-mannheim.de/wordpress/wp-content/uploads/2017/10/Shotton-LOC-DB-Mannheim.pdf (David Shotton)
GARR Conference 2017, Venice, 16 November 2017, https://www.eventi.garr.it/it/documenti/conferenza-garr-2017/presentazioni-2/232-conf2017-presentazione-peroni/file (Silvio Peroni)
OpenCon 2017, Oxford, 1 December 2017, https://doi.org/10.6084/m9.figshare.5844981.v1 (David Shotton)
PIDapalooza Conference of Persistent Identifiers, Girona, 24 January 2018, https://doi.org/10.6084/m9.figshare.5844972.v2 (David Shotton)
2018 International Workshop on Semantics, Analytics, Visualisation: Enhancing Scholarly Dissemination, Lyon, 24 April 2018, https://doi.org/10.6084/m9.figshare.7531577.v1 (Ivan Heibi)
Workshop on Open Citations 2018, Bologna, 3 September 2018, https://workshop-oc.github.io/presentations/D1S3_David_Shotton.pdf (David Shotton)
Workshop on Open Citations 2018, Bologna, 4 September 2018, https://docs.google.com/presentation/d/1mybQmjhFY6kLtTE1TdONaxsl0nSjmRGOSCnFMTwfzWQ/edit?usp=sharing (Silvio Peroni)
The 5th Conference on Scholarly Publishing in the Context of Open Science (PUBMET 2018), Zadar, 20 September 2018, https://doi.org/10.6084/m9.figshare.7110653.v3 (Silvio Peroni)
The 17th International Semantic Web Conference (ISWC 2018), Monterey, 12 October 2018, https://doi.org/10.6084/m9.figshare.7151759.v1 (Silvio Peroni)
WikiCite Conference 2018, Berkeley, 27 November 2018, https://doi.org/10.6084/m9.figshare.7396667.v1 (Ivan Heibi)
A further presentation on Open Citation Identifiers will be given at the 2019 PIDapalooza Conference of Persistent Identifiers in Dublin in January 2019.
We also wish to develop effective graphical user interfaces to explore the citation network, and analytical tools over our open data. Since the OCC and COCI data are all open and available for others also to build such tools, we anticipate that such developments will best be undertaken collaboratively, under some open community organization, and indeed such development is currently being undertaken in collaboration with colleagues from CWTS at the University of Leiden, famous for their development of VOSviewer.
In order to fully support open scholarship, OpenCitations need to mature from being an academic research and development project to become a recognised scholarly infrastructure service such as PubMed. We wish to avoid becoming a commercial company, and see our development better served by being ‘adopted’ by a major established scholarly institution such as national or university library or an internationally recognised centre providing scholarly bibliographic services, that has already shown a commitment to open scholarship, where the interaction between that institution and OpenCitations would be mutually beneficial. To this end, we are currently in the mid-phase of negotiations with two institutions.
Ivan Heibi, Silvio Peroni, David Shotton (2018a). Enabling text search on SPARQL-endpoints through OSCAR. Submitted for publication to Data Science – Methods, Infrastructure, and Applications. OA at at https://w3id.org/people/essepuntato/papers/oscar-datascience2019/
Ivan Heibi, Silvio Peroni, David Shotton (2018b). OSCAR: A Customisable Tool for Free-Text Search over SPARQL Endpoints. In Semantics, Analytics, Visualization – 3rd International Workshop, SAVE-SD 2017, and 4th International Workshop, SAVE-SD 2018, Revised Selected Papers: 121-137. DOI: https://doi.org/10.1007/978-3-030-01379-0_9, OA at https://w3id.org/people/essepuntato/papers/oscar-savesd2018.html
Silvio Peroni, Alexander Dutton, Tanya Gray, David Shotton (2015). Setting our bibliographic references free: towards open citation data. Journal of Documentation, 71: 253-77. DOI: https://doi.org/10.1108/JD-12-2013-0166, OA at http://speroni.web.cs.unibo.it/publications/peroni-2015-setting-bibliographic-references.pdf
Silvio Peroni, David Shotton (2018a). OpenCitations: enabling the FAIR use of open citation data. In Proceedings of the GARR Conference 2017 – The data way to Science – Selected Papers. DOI: https://doi.org/10.26314/GARR-Conf17-proceedings-19
Silvio Peroni, David Shotton (2018b). Open Citation: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.6683855.v1
Silvio Peroni, David Shotton (2018c). Open Citation Identifier: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.7127816.v1
Silvio Peroni, David Shotton (2018d). The OpenCitations Data Model. Figshare. DOI: https://doi.org/10.6084/m9.figshare.3443876.v5
Silvio Peroni, David Shotton (2018e). The SPAR Ontologies. In Proceedings of the 17th International Semantic Web Conference (ISWC 2018): 119-136. DOI: https://doi.org/10.1007/978-3-030-00668-6_8
Silvio Peroni, David Shotton, Fabio Vitali (2016a). Building Citation Networks with SPACIN. Knowledge Engineering and Knowledge Management – EKAW 2016 Satellite Events, EKM and Drift-an-LOD, Revised Selected Papers: 162-166. DOI: https://doi.org/10.1007/978-3-319-58694-6_23, OA at https://w3id.org/oc/paper/spacin-demo-ekaw2016.html
Silvio Peroni, David Shotton, Fabio Vitali (2016b). Freedom for bibliographic references: OpenCitations arise. In Proceedings of 2016 International Workshop on Linked Data for Information Extraction (LD4IE 2016): 32-43. http://ceur-ws.org/Vol-1699/paper-05.pdf
Silvio Peroni, David Shotton, Fabio Vitali (2017). One year of the OpenCitations Corpus: Releasing RDF-based scholarly citation data into the Public Domain. In Proceedings of the 16th International Semantic Web Conference (ISWC 2017): 184-192. DOI: https://doi.org/10.1007/978-3-319-68204-4_19, OA at https://w3id.org/people/essepuntato/papers/oc-iswc2017.html
David Shotton (2013). Open citations. Nature, 502: 295-297. https://doi.org/10.1038/502295a
David Shotton (2018). Funders should mandate open citations. Nature 553: 129. https://doi.org/10.1038/d41586-018-00104-7
The OpenCitations Enhancement Project – final report
The OpenCitations Enhancement Project
Final report for the Alfred P. Sloan Foundation
Report period: 1st May 2017 – 30 November 2018.Report written: 30th December 2018
Background
OpenCitations (http://opencitaitons.net) is a scholarly infrastructure organization dedicated to open scholarship and the publication of open bibliographic and citation data by the use of Semantic Web (Linked Data) technologies, and engaged in advocacy for semantic publishing and open citations [Peroni and Shotton, 2018b]. It provides the OpenCitations Data Model [Peroni and Shotton, 2018d], the SPAR (Semantic Publishing and Referencing) Ontologies [Peroni and Shotton, 2018e] for encoding scholarly bibliographic and citation data in RDF, and open software of generic applicability for searching, browsing and providing APIs over RDF triplestores. It has developed the OpenCitations Corpus (OCC) [Peroni et al., 2017] of open downloadable bibliographic and citation data recorded in RDF, and a system and resolution service for Open Citation Identifiers (OCIs) [Peroni and Shotton, 2018c], and it is currently developing a number of Open Citation Indexes using the data openly available in third-party bibliographic databases.The Directors of OpenCitations are David Shotton, Oxford e-Research Centre, University of Oxford (david.shotton@opencitations.net), and Silvio Peroni, Digital Humanities Advanced Research Centre, Department of Classical Philology and Italian Studies, University of Bologna (silvio.peroni@opencitations.net). We are committed to open scholarship, open data, open access publication, and open source software. We espouse the FAIR data principles developed by Force11, of which David Shotton was a founding member (https://www.force11.org/group/fairgroup/fairprinciples), and the aim of the Initiative for OpenCitations (I4OC, https://i4oc.org), of which both David Shotton and Silvio Peroni were founding members, to promote the availability of citation data that is structured, separable, and open.
Project personnel and roles
Ivan Heibi – Research Fellow
Ivan Heibi was appointed to the 12 months Research Fellowship position funded by the Sloan Foundation.Ivan has been responsible for the development of new visualization and programming interfaces for exploring and making sense of the citation data included in the OCC and in the new OpenCitations Indexes, for the main part of the scripts related to the population and regular maintenance of COCI (The OpenCitations Index of Crossref open DOI-to-DOI citations, the first of the OpenCitations Indexes), and for conference presentations and paper writing.
Silvio Peroni – Lead Applicant and Principal Investigator
Silvio has been responsible for project management, for interview, appointment and supervision of the work of Ivan Heibi, for all aspects of software coding and technical developments required for the OpenCitations Corpus (OCC), the OpenCitations Indexes, and the Open Citation Identifier Resolution Service, for the ordering and management of new Sloan-funded hardware, and for conference presentations, paper writing and other forms of outreach and dissemination (e.g. blog and social networks).David Shotton – Consultant Co-Investigator
David has been responsible for project management, interaction with publishers, conference presentations, paper writing, other forms of outreach and dissemination (e.g. blog and social networks), for web site and data model revision, and for independent usability evaluation, stress-testing and design feedback of new user interfaces and applications.Project management
Project management has been straightforward, as should be the case, given the small size of our team. It has involved more than 1500 e-mail exchanges between David Shotton and Silvio Peroni, about 500 e-mail exchanges between Silvio Peroni and Ivan Heibi since November 2017, two dozen or so video conferences, some of which have involved collaborators, and an extended face-to-face meeting during the WikiCite 2017 Conference in Vienna at the start of the project and the Workshop on Open Citations 2018 in Bologna.We have together harmoniously developed the concept of and vision for OpenCitations as an infrastructure organization, the structure and content of the OpenCitations web site (http://opencitaitons.net), the classes and properties of our supporting SPAR ontologies (http://www.sparontologies.net), and the community of collaborators and users of our developments. This has involved outreach and dissemination at a number of international research conferences, involvement with publishers through the Initiative for Open Citations, and associated publications.
We have studied and preliminarily tested a new scalable architecture centred on one powerful independent physical server, that both stores and handles all the data in the Corpus and in the new OpenCitations Indexes, and also offers adequate performance for query services. This server is supplemented by 30 additional small physical machines, Raspberry Pi 3Bs, working in parallel, each in charge of ingesting a defined set of reference lists and feeding the ingested data to the central server for further processing and storage as RDF in our Blazegraph triplestore.
Current status of the OpenCitations services
Currently, we release two different datasets – the OpenCitations Corpus and COCI, the OpenCitations Index of Crossref open DOI-to-DOI citations – and several interfaces so as to make these data queryable from different access points.Functionality and holdings
As of 29th December 2018, the OpenCitations Corpus (OCC) contains information about 13,964,148 citation links to 7,565,367 cited resources, ingested from 326,743 citing bibliographic resources obtained from the Open Access corpus of Europe PubMed Central and from the citation data imported from the EXCITE project. The main part of the development effort in the past months has been spent in implementing ingestion strategies that allow partners to provide us citation data, stored according the OpenCitations Data Model [Peroni and Shoton, 2018b], so as to be added directly into the Corpus. In September 2018, we successfully completed the ingestion of the initial data coming from the EXCITE project (citations from social sciences scholarly papers published by German publishers), and we are actively interacting with the LOC-DB project and the Venice Scholar Index so as to add their data to the OCC as well. In ongoing work, we are also collaborating with arXiv and EXCITE to harvest all the references from all PDF documents in the arXiv ePrints collection, to record these in RDF according to the OpenCitations Data Model, and to ingest them into the OpenCitations Corpus, as well as creating a new Index of these citations.The first of these OpenCitations Indexes is COCI, the OpenCitations Index of Crossref open DOI-to-DOI citations, an RDF dataset containing details of all the citations that are specified by the open references to DOI-identified works present in Crossref, as of the latest COCI update. COCI does not index Crossref references that are closed, nor Crossref references to entities that lack DOIs. These citations are treated as first-class data entities, with accompanying properties including the citations timespan and possible kinds of self-citation characteristics, modelled according to the index data model described in the OpenCitations Indexes page. COCI was launched in July 2018, and the most recent update of COCI is dated 12 November 2018. It presently contains 449,840,503 citations between 46,534,705 bibliographic resources. COCI is the first citation index released by OpenCitations, being a bibliographic index recording citations between publications that permits the user to establish which later documents cite earlier documents, and to create citation graphs of these citations.).
While full coverage of the scholarly citation graph depicted by the aforementioned datasets (or as full as practically possible) is required for the calculation of certain bibliometric indicators such as journal impact factors and individual h-indexes (Hirsch numbers), partial coverage while OCC grows is still of value, since it includes citations of all the most important biomedical papers obtained from the Open Access Subset off PubMed Central. These can be easily recognized by their large number of inward citation links, and can be used to explore the development of disciplines and research trends. In addition, COCI, with its wider scope, has sufficient coverage to be used for large-scale bibliometrics analysis.
Purchase of new hardware, and testing and development of new software
Because of unavoidable academic teaching commitments for Silvio Peroni, the installation of the new Sloan-funded hardware for OCC, purchased in autumn 2017, had to be postponed. All the services (old and new) of OpenCitations were successfully transferred to our new server in October 2018. In order to implement such transition, the ingestion process of the OCC was halted, so as to allow Silvio Peroni to properly test the new hardware and to extend the existing ingestion software so as to be usable within the new parallel processing architecture. The final tests are currently running, and we will recommence the full ingestion process of the OCC using the new hardware configuration, with its greatly enhanced ingest rate, in January 2019. In the meantime, the new infrastructure has been used to allow us to create COCI, so far the largest RDF dataset of open citation data available worldwide.In addition, we have completed the transition of all the OpenCitations software from the old GitHub repository (i.e. https://github.com/essepuntato/opencitations) to a new GitHub organization, namely https://github.com/opencitations. This organisation includes several repositories which permit third parties to initiate the whole suite of OpenCitations software on a local machine. This is of key importance for the resilience of this open source project.
User interfaces
SPARQL, the query language used to interrogate RDF triplestores, is a quite powerful language. However, one needs appropriate skills with Semantic Web technologies to master it for solving even easy search tasks. Thus normal web users are unable to use appropriately such technologies if not appropriately instructed, leaving all these technologies in the hands of a limited number of experts. The datasets made available by OpenCitations suffered similar issues.Initially, the goal we had was to develop ad-hoc user interfaces to abstract the complexities of the SPARQL endpoints into well-designed Web interfaces that anyone could use. During the development, though, we thought it would be better to develop generic frameworks for building customizable interfaces that allow one to expose, in a more human-understandable way, RDF data stored in any RDF triplestore and accessible through any SPARQL-endpoint, so as to forster reuse of such software in contexts that, in principle, might go far beyond the OpenCitations domain.
To this end we developed three different open software applications:
- OSCAR [Heibi et al., 2018a] [Heibi et al., 2018b], a Javascript application for creating textual search interfaces to RDF data;
- LUCINDA, another Javascript application for creating Web browsers over RDF data;
- RAMOSE, a Python application that permits one to easily create and serve a conventional HTTP REST API over a SPARQL endpoint.
All these applications have been used to produce several interfaces to all the datasets released by OpenCitations. In particular, we have created user-friendly textual search interfaces (via OSCAR) both for the OCC (see the search box now on the OpenCitations home page, and the related search page) and for COCI (see the related search page). We have additionally developed browsing applications (via LUCINDA) to permit humans an easier navigation of all the entities included in the OCC (e.g. see the bibliographic resource br/1791056) and in COCI (e.g. see the citation oci:02001010806360107050663080702026306630509-02001010806360107050663080702026305630301). Finally, we have also implemented REST HTTP APIs (via RAMOSE) for simplifying the queries to both datasets, the OCC and COCI, by Web developers with no expertise in Semantic Web technologies.
In addition, in order to demonstrate its flexibility, we have also created two web pages using OSCAR, LUCINDA, and RAMOSE for permitting similar tasks (text query, browsing, and REST APIs) on the scholarly data in Wikidata / WikiCite – another project recently funded by the Alfred P. Sloan Foundation. These interfaces have been introduced in two distinct event: during the hack day of the Workshop on Open Citations 2018 and during the WikiCite 2018 Conference.
A further prototypical interface / service has been recently proposed so as to try to gather additional open citation data to include in the OCC, involving users of the scholarly domain such as editors and researchers. This application is called BCite [Daquino et al., 2018]. BCite is designed to provide a full workflow for citation discovery, allowing users to specify the references as provided by the authors of an article, to retrieve them in the required format and style, to double-check their correctness, and, finally, to create new open citation data according to the OpenCitations Data Model [Peroni and Shotton, 2018d], so as to permit their future integration into the OCC. While presently only a prototype, we received several commendations for this tool, and we are currently studying funding strategies to develop a full standalone application that can be used by anyone and that allows users to directly interact with the OCC, so as to upload new data into the Corpus.
Open Citation Identifiers
During the reporting period, it became increasingly evident to us that citations deserved treating as First Class Data Entities, which would give the following advantages:- All the information regarding each citation would be available in one place.
- Citations become easier to describe, distinguish, count and process.
- If available in aggregate, citations become easier to analyze using bibliometric methods, for example to determine how citation time spans vary by discipline.
- The metadata describing the citation must be definable in a machine-readable manner.
- Such metadata must be storable, searchable and retrievable.
- Each citation must be identifiable, using a globally unique Persistent Identifier.
- There must be a Web-based resolution service that takes the identifier as input and returns a description of the citation.
- the first requirement by the addition of appropriate classes and properties to CiTO, the Citation Typing Ontology, and by the addition of a new member of the class datacite:ResourceIdentifierScheme in the DataCite Ontology, namely Open Citation Identifier;
- the second requirement by modifying the OpenCitations Data Model [Peroni and Shotton, 2018d] so that citations can be properly described using these new ontology terms within the OpenCitations Corpus;
- the third requirement by creating the syntax for this new Open Citation Identifier (OCI) [Peroni and Shotton, 2018c], and enabling the creation of such identifiers, both to specify citations within the OpenCitations Corpus, and also (importantly) to specify citations described in Wikidata (by QIDs) and in Crossref (by DOIs); and
- the fourth requirement by creating a resolving service for OCIs at http://opencitations.net/oci and additional software (in Python) for retrieving information about a particular citation identified by an OCI.
Collaborations and Users
OpenCitations Data Model
We are collaborating with the following groups and academic projects, both to promote the use of the OpenCitations Data Model (OCDM), and to provide a publication venue for the citation data that they are liberating from the scholarly literature:- Matteo Romanello of the Digital Humanities Laboratory at the University of Lausanne is using OCDM for modelling citations of the classical literature within ancient Venetian documents in the context of the Venice Scholar Index, and is currently working on producing a dataset of citation data compliant with OCDM so as to be ingested in the OCC.
- Two DFG-funded German projects that are extracting citations from Social Science publications:
- The Linked Open Citations Database (LOC-DB) at the University of Mannheim is using OCDM to model their data, with the aim of producing them accordigly with such model so as to be ingested in the OCC.
- Steffen Staab (University of Koblenz) and Philipp Mayr (GESIS) are running the EXCITE Project, which uses OCDM to model their citation data, and already adopted the OCC as their publication platform. In fact, in September 2018, ~1 million citations coming from the EXCITE Project were successfully ingested in the OCC.
- Sergey Parinov is technically leading CitEcCyr, which is an open repository of citation relationships obtained from research papers in the Russian language and Cyrillic script. This project intends to model its citations using the OCDM, and will use the OpenCitations Corpus as its publication platform.
Users of OpenCitations data
The following project and organizations have let us know that they are using data from the OCC and COCI:- Wikidata includes alignments between several bibliographic entries with OCC resources;
- OpenAIRE imported OCC metadata about articles into their LOD database;
- Daniel Ecer and Lisa Knoll of eLife performed analytics on the OCC data;
- Ontotext demonstrated SPARQL query federation between Springer Nature LOD and OCC;
- Anna Kamińska published a bibliometrics case study of PLOS ONE articles in OCC;
- Daniel Himmelstein processed OpenCitations data to create DOI-to-DOI citation tables;
- Thiago Nunes and Daniel Schwabe are using OCC to exemplify their XPlain framework;
- Antonina Dattolo and Marco Corbatto are using the OCC as source for VisualBib framework;
- Nees Jan van Eck and Ludo Waltman extended VOSviewer so as to use data in the OCC + COCI, that will be officially published in the next release of the tool;
- Barney Walker developed Citation Gecko, a graph-based citation discovery tool based on the OCC and COCI for retrieving citation data about the papers;
- Philipp Zumstein developed a Zotero plugin that gives information about open citations using COCI;
- Dominique Rouger developed a Web application that provides a visual graph representation of citation links in COCI.
Website statistics
From May 2017 to November 2018, the official OpenCitations website has been accessed ~5.8M times – we have excluded from this list the hits done by well-known spiders and crawlers. It is worth mentioning that the pages related to the data available and the services for querying them (i.e. “/corpus”, “/sparql”, and “/index” in the following diagram) have together gained a very high percentage of the overall accesses, showing that the main reason people access the OpenCitations website is to explore and use the data in the OCC and in COCI. It is also clear how the introduction of COCI brought additional accesses to the OpenCitations services, and the trend is increasing – e.g. in December 2018 (not shown in the following diagram) we got more than 200M accesses to “/index”, mainly related to the use of the COCI REST APIs.
Community outreach
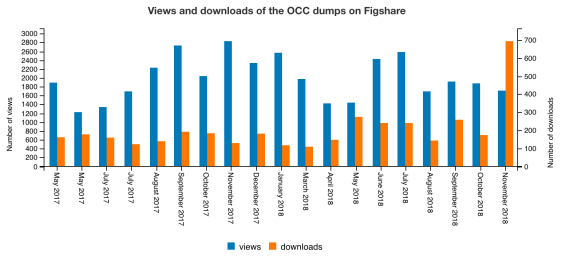
From May 2017 to November 2018, the documents (i.e. [Peroni and Shotton, 2018b] [Peroni and Shotton, 2018c] [Peroni and Shotton, 2018d]) and the dumps of the OCC and of COCI available on Figshare (see http://opencitations.net/download) have been viewed 37,960 times and downloaded 3,842 times. The figure below summarizes how many views and downloads such resources have received month by month. For example, the latest version of COCI in CSV has been downloaded 239 times since its release in November (see https://doi.org/10.6084/m9.figshare.6741422.v3).


Users of the SPAR Ontologies
The SPAR Ontologies [Peroni and Shotton, 2018e] are in use by about 40 other projects and organizations, including:- The United States Global Change Information System, which encodes federal information relating to climate change, makes extensive use of SPAR ontology terms.
- The United Nations Document Ontology (UNDO) has been specifically aligned with FaBiO.
- Wikidata has many classes that have been alighted with FaBiO or CiTO.
- DBPedia’s DataID ontology uses the FaBiO and DataCite ontologies.
- W3C’s Data on the Web Best Practices: Dataset Usage Vocabulary uses SPAR Ontologies.
To date, as far as we are aware, more than 677 papers have been published that cite or use one or more of the SPAR ontologies. For the full list, see http://www.sparontologies.net/uptake#publications.
OpenCitations and the Initiative for Open Citations
OpenCitations and the Initiative for Open Citations, despite the similarity of title, are two distinct organizations. The primary purpose of OpenCitations is to host and build the OpenCitations Corpus (OCC) and the OpenCitations Indexes, as long as additional service to browse, query, and analyse citation data. In contrast, the Initiative for Open Citations (I4OC, https://i4oc.org) is separate and independent organization, whose founding was spearheaded by Dario Taraborelli of the WikiMedia Foundation. OpenCitations is one of several founding members of the Initiative for Open Citations, as documented at https://i4oc.org/#founders. I4OC is a pressure group to promote the unrestricted availability of scholarly citation data, but does not itself host citation data.Because open reference lists are necessary for the population of OCC, we at OpenCitations have devoted considerable effort to promoting I4OC’s aims, and we host the I4OC web site on behalf of that community.
Within a short space of time, I4OC has persuaded most of the major scholarly publishers to open their reference lists submitted to Crossref, so that the proportion of all references submitted to Crossref that are now open has risen from 1% to over 50%. These are now available for OpenCitations to harvest into the OpenCitations Corpus and publish in RDF, as well as for others to harvest and use as they wish [Shotton, 2018].
Publications during the reporting period
Scholarly papers
Marilena Daquino, Ilaria Tiddi, Silvio Peroni, David Shotton (2018). Creating Open Citation Data with BCite. In Emerging Topics in Semantic Technologies – ISWC 2018 Satellite Events: 83-93. DOI: https://doi.org/10.3233/978-1-61499-894-5-83, OA at http://ceur-ws.org/Vol-2184/paper-01.pdfIvan Heibi, Silvio Peroni, David Shotton (2018). Enabling text search on SPARQL-endpoints through OSCAR. Submitted for publication to Data Science – Methods, Infrastructure, and Applications. OA at at https://w3id.org/people/essepuntato/papers/oscar-datascience2019/
Ivan Heibi, Silvio Peroni, David Shotton (2018). OSCAR: A Customisable Tool for Free-Text Search over SPARQL Endpoints. In Semantics, Analytics, Visualization – 3rd International Workshop, SAVE-SD 2017, and 4th International Workshop, SAVE-SD 2018, Revised Selected Papers: 121-137. DOI: https://doi.org/10.1007/978-3-030-01379-0_9, OA at https://w3id.org/people/essepuntato/papers/oscar-savesd2018.html
Silvio Peroni, David Shotton (2018). OpenCitations: enabling the FAIR use of open citation data. In Proceedings of the GARR Conference 2017 – The data way to Science – Selected Papers. DOI: https://doi.org/10.26314/GARR-Conf17-proceedings-19
Silvio Peroni, David Shotton (2018). The SPAR Ontologies. In Proceedings of the 17th International Semantic Web Conference (ISWC 2018): 119-136. DOI: https://doi.org/10.1007/978-3-030-00668-6_8
Silvio Peroni, David Shotton, Fabio Vitali (2017). One year of the OpenCitations Corpus: Releasing RDF-based scholarly citation data into the Public Domain. In Proceedings of the 16th International Semantic Web Conference (ISWC 2017): 184-192. DOI: https://doi.org/10.1007/978-3-319-68204-4_19, OA at https://w3id.org/people/essepuntato/papers/oc-iswc2017.html
David Shotton (2018). Funders should mandate open citations. Nature 553: 129. https://doi.org/10.1038/d41586-018-00104-7
Additional documents
Silvio Peroni, David Shotton (2018). Open Citation: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.6683855.v1Silvio Peroni, David Shotton (2018). Open Citation Identifier: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.7127816.v1
Silvio Peroni, David Shotton (2018). The OpenCitations Data Model. Figshare. DOI: https://doi.org/10.6084/m9.figshare.3443876.v5
Blog posts
6 May 2017: Querying the OpenCitations Corpus15 May 2017: The Sloan Foundation funds OpenCitations
24 Nov 2017: Milestone for I4OC – open references at Crossref exceed 50%
24 Nov 2017: Elsevier references dominate those that are not open at Crossref
28 Nov 2017: Openness of non-Elsevier references
9 Jan 2018: The new Crossref reference distribution policy
9 Jan 2018: Barriers to comprehensive reference availability
15 Jan 2018: Funders should mandate open citations
16 Jan 2018: Oxford University Press opens its references!
29 Jan 2018: OpenCitations and the Initiative for Open Citations: A Clarification
19 Feb 2018: Citations as First-Class Data Entities: Introduction
22 Feb 2018: Citations as First-Class Data Entities: Citation Descriptions
25 Feb 2018: Citations as First-Class Data Entities: The OpenCitations Data Model
4 Mar 2018: Citations as First-Class Data Entities: The OpenCitations Corpus
12 Mar 2018: Citations as First-Class Data Entities: Open Citation Identifiers
15 Mar 2018: Citations as First-Class Data Entities: The Open Citation Identifier Resolution Service
23 Mar 2018: Early adopters of the OpenCitations Data Model
17 Apr 2018: Workshop on Open Citations
12 Jul 2018: COCI, the OpenCitations Index of Crossref open DOI-to-DOI references
19 Nov 2018: New release of COCI: 450M DOI-to-DOI citation links now available
Conference presentations and other outreach
Workshop on Open Citations 2018
OpenCitations, the EXCITE Project and Europe PubMed Central ran the first Workshop on Open Citations (Twitter: @workshop_oc) at the University of Bologna in Bologna, Italy, on 3-5 September 2018. It was organised as follows:- Day One and Day Two: Formal presentations and discussions on the creation, availability, uses and applications of open bibliographic citations, and of bibliometric studies based upon them;
- Day Three: A Hack Day on Open Citations to see what services can be prototyped using large volumes of open citation data.
- Opening up citations: Initiatives, collaborations, methods and approaches for the creation of open access to bibliographic citations;
- Policies and funding: Strategies, policies and mandates for promoting open access to citations, and transparency and reproducibility of research and research evaluation;
- Publishers and learned societies: Approaches to, benefits of, and issues surrounding the deposit, distribution, and services for open bibliographic metadata and citations;
- Projects: Metrics, visualizations and other projects. The uses and applications of open citations, and bibliometric analyses and metrics based upon them.
A further Workshop on Open Citations is being planned for autumn 2019.
Presentations
We have made conference presentations on OpenCitations, the Initiative for Open Citations, and Open Citation Identifiers at the following international conferences and workshops:WikiCite Conference 2017, Vienna, 23 May 2017, https://www.slideshare.net/essepuntato/opencitations (Silvio Peroni and David Shotton)
COASP 9, 9th Conference of Open Access Scholarly Publishing, Lisbon, 20 September 2017, https://www.slideshare.net/essepuntato/the-initiative-for-open-citations-and-the-opencitations-corpus (David Shotton)
SemSci 2017, 1st International Workshop on Enabling Open Semantic Science, Vienna, 21 October 2017, https://w3id.org/people/essepuntato/presentations/the-open-citations-revolution.html (Silvio Peroni)
ISWC 2017, 16th International Semantic Web Conference, Vienna, 24 October 2017, https://w3id.org/people/essepuntato/presentations/oc-iswc2017.html (Silvio Peroni)
FORCE 2017, Research Communication and e-Scholarship Conference, Berlin, 27 October 2017, http://w3id.org/people/essepuntato/presentations/oc-force2017.html (Silvio Peroni)
Linked Open Citation Database (LOC-DB) Workshop, Mannheim, 7 November 2017, https://locdb.bib.uni-mannheim.de/wordpress/wp-content/uploads/2017/10/Shotton-LOC-DB-Mannheim.pdf (David Shotton)
GARR Conference 2017, Venice, 16 November 2017, https://www.eventi.garr.it/it/documenti/conferenza-garr-2017/presentazioni-2/232-conf2017-presentazione-peroni/file (Silvio Peroni)
OpenCon 2017, Oxford, 1 December 2017, https://doi.org/10.6084/m9.figshare.5844981.v1 (David Shotton)
PIDapalooza Conference of Persistent Identifiers, Girona, 24 January 2018, https://doi.org/10.6084/m9.figshare.5844972.v2 (David Shotton)
2018 International Workshop on Semantics, Analytics, Visualisation: Enhancing Scholarly Dissemination, Lyon, 24 April 2018, https://doi.org/10.6084/m9.figshare.7531577.v1 (Ivan Heibi)
Workshop on Open Citations 2018, Bologna, 3 September 2018, https://workshop-oc.github.io/presentations/D1S3_David_Shotton.pdf (David Shotton)
Workshop on Open Citations 2018, Bologna, 4 September 2018, https://docs.google.com/presentation/d/1mybQmjhFY6kLtTE1TdONaxsl0nSjmRGOSCnFMTwfzWQ/edit?usp=sharing (Silvio Peroni)
The 5th Conference on Scholarly Publishing in the Context of Open Science (PUBMET 2018), Zadar, 20 September 2018, https://doi.org/10.6084/m9.figshare.7110653.v3 (Silvio Peroni)
The 17th International Semantic Web Conference (ISWC 2018), Monterey, 12 October 2018, https://doi.org/10.6084/m9.figshare.7151759.v1 (Silvio Peroni)
WikiCite Conference 2018, Berkeley, 27 November 2018, https://doi.org/10.6084/m9.figshare.7396667.v1 (Ivan Heibi)
A further presentation on Open Citation Identifiers will be given at the 2019 PIDapalooza Conference of Persistent Identifiers in Dublin in January 2019.
Tweets
We have tweeted about the project and related matters under the names @opencitations, @dshotton, @essepuntato, @ivanHeiB, @workshop_oc, and @i4oc_org.Future sustainability
While presently the OpenCitations Corpus has only partial coverage, our aim is that OpenCitations should become a comprehensive source of open citation information from all disciplines of scholarly endeavour, used on a daily basis by scholars worldwide, to equal or better the commercial offerings from Clarivate Analytics (Web of Science) and Elsevier (Scopus).We also wish to develop effective graphical user interfaces to explore the citation network, and analytical tools over our open data. Since the OCC and COCI data are all open and available for others also to build such tools, we anticipate that such developments will best be undertaken collaboratively, under some open community organization, and indeed such development is currently being undertaken in collaboration with colleagues from CWTS at the University of Leiden, famous for their development of VOSviewer.
In order to fully support open scholarship, OpenCitations need to mature from being an academic research and development project to become a recognised scholarly infrastructure service such as PubMed. We wish to avoid becoming a commercial company, and see our development better served by being ‘adopted’ by a major established scholarly institution such as national or university library or an internationally recognised centre providing scholarly bibliographic services, that has already shown a commitment to open scholarship, where the interaction between that institution and OpenCitations would be mutually beneficial. To this end, we are currently in the mid-phase of negotiations with two institutions.
Conclusions
The grantees wish to express their deep gratitude to the Alfred P. Sloan Foundation for financial support enabling them to undertake the OpenCitations Enhancement Project, without which the rapid developments reported here would not have been possible.References
Marilena Daquino, Ilaria Tiddi, Silvio Peroni, David Shotton (2018). Creating Open Citation Data with BCite. In Emerging Topics in Semantic Technologies – ISWC 2018 Satellite Events: 83-93. DOI: https://doi.org/10.3233/978-1-61499-894-5-83, OA at http://ceur-ws.org/Vol-2184/paper-01.pdfIvan Heibi, Silvio Peroni, David Shotton (2018a). Enabling text search on SPARQL-endpoints through OSCAR. Submitted for publication to Data Science – Methods, Infrastructure, and Applications. OA at at https://w3id.org/people/essepuntato/papers/oscar-datascience2019/
Ivan Heibi, Silvio Peroni, David Shotton (2018b). OSCAR: A Customisable Tool for Free-Text Search over SPARQL Endpoints. In Semantics, Analytics, Visualization – 3rd International Workshop, SAVE-SD 2017, and 4th International Workshop, SAVE-SD 2018, Revised Selected Papers: 121-137. DOI: https://doi.org/10.1007/978-3-030-01379-0_9, OA at https://w3id.org/people/essepuntato/papers/oscar-savesd2018.html
Silvio Peroni, Alexander Dutton, Tanya Gray, David Shotton (2015). Setting our bibliographic references free: towards open citation data. Journal of Documentation, 71: 253-77. DOI: https://doi.org/10.1108/JD-12-2013-0166, OA at http://speroni.web.cs.unibo.it/publications/peroni-2015-setting-bibliographic-references.pdf
Silvio Peroni, David Shotton (2018a). OpenCitations: enabling the FAIR use of open citation data. In Proceedings of the GARR Conference 2017 – The data way to Science – Selected Papers. DOI: https://doi.org/10.26314/GARR-Conf17-proceedings-19
Silvio Peroni, David Shotton (2018b). Open Citation: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.6683855.v1
Silvio Peroni, David Shotton (2018c). Open Citation Identifier: Definition. Figshare. DOI: https://doi.org/10.6084/m9.figshare.7127816.v1
Silvio Peroni, David Shotton (2018d). The OpenCitations Data Model. Figshare. DOI: https://doi.org/10.6084/m9.figshare.3443876.v5
Silvio Peroni, David Shotton (2018e). The SPAR Ontologies. In Proceedings of the 17th International Semantic Web Conference (ISWC 2018): 119-136. DOI: https://doi.org/10.1007/978-3-030-00668-6_8
Silvio Peroni, David Shotton, Fabio Vitali (2016a). Building Citation Networks with SPACIN. Knowledge Engineering and Knowledge Management – EKAW 2016 Satellite Events, EKM and Drift-an-LOD, Revised Selected Papers: 162-166. DOI: https://doi.org/10.1007/978-3-319-58694-6_23, OA at https://w3id.org/oc/paper/spacin-demo-ekaw2016.html
Silvio Peroni, David Shotton, Fabio Vitali (2016b). Freedom for bibliographic references: OpenCitations arise. In Proceedings of 2016 International Workshop on Linked Data for Information Extraction (LD4IE 2016): 32-43. http://ceur-ws.org/Vol-1699/paper-05.pdf
Silvio Peroni, David Shotton, Fabio Vitali (2017). One year of the OpenCitations Corpus: Releasing RDF-based scholarly citation data into the Public Domain. In Proceedings of the 16th International Semantic Web Conference (ISWC 2017): 184-192. DOI: https://doi.org/10.1007/978-3-319-68204-4_19, OA at https://w3id.org/people/essepuntato/papers/oc-iswc2017.html
David Shotton (2013). Open citations. Nature, 502: 295-297. https://doi.org/10.1038/502295a
David Shotton (2018). Funders should mandate open citations. Nature 553: 129. https://doi.org/10.1038/d41586-018-00104-7
No comments:
Post a Comment