In order to improve the quality of systematic researches, various tools have been developed by well-known scientific institutes sporadically. Dr. Nader Ale Ebrahim has collected these sporadic tools under one roof in a collection named “Research Tool Box”. The toolbox contains over 720 tools so far, classified in 4 main categories: Literature-review, Writing a paper, Targeting suitable journals, as well as Enhancing visibility and impact factor.
Wednesday, 5 June 2019
Characterizing Scientific Impact with PageRank — Part I
It’s
often said that academics live and die by the citation sword. I’m
currently in academia, and I’d say that’s true in my discipline. In this
blog, I’ll share some results from a side project I’ve undertaken to
learn about networks by using alternative metrics for gauging scientific
impact. In particular, evaluating the impact of a publication and the
cumulative impact of an author, through PageRank — the algorithm that
Google’s search engine was originally based on — rather than the usual
metrics, such as total number of citations.
Let
me give some overview on my discipline before proceeding further. I’m
in the field of particle physics (aka “High Energy Physics”). I would
say the field comprises some 10,0000 physicists or so, divided into two
categories: theoreticians, and experimentalists. I belong to the former.
The field is relatively open and collegial, which is a great thing.
We
(ultimately) publish our results in peer-reviewed journals, and while
refereed papers are certainly still an important metric — particularly
for promotions, major discoveries by experimentalists, etc — virtually
everyone looks at papers on the arXiv
where the pre-print versions of papers are published. As reputation is a
major currency in science, it’s only after the pre-print version has
been unofficially peer-reviewed by the community, that it’s submitted to
a journal.
Another great resource in HEP is InspireHEP,
which is a powerful database where you can search for papers published
in either a peer-reviewed journal or on the arXiv (or both), as well as
search for authors, etc. InspireHEP allows you to look up the scientific
statistics of any author. For instance, the cumulative stats on Steven
Weinberg, a Nobel Prize winner in physics, can be found here:
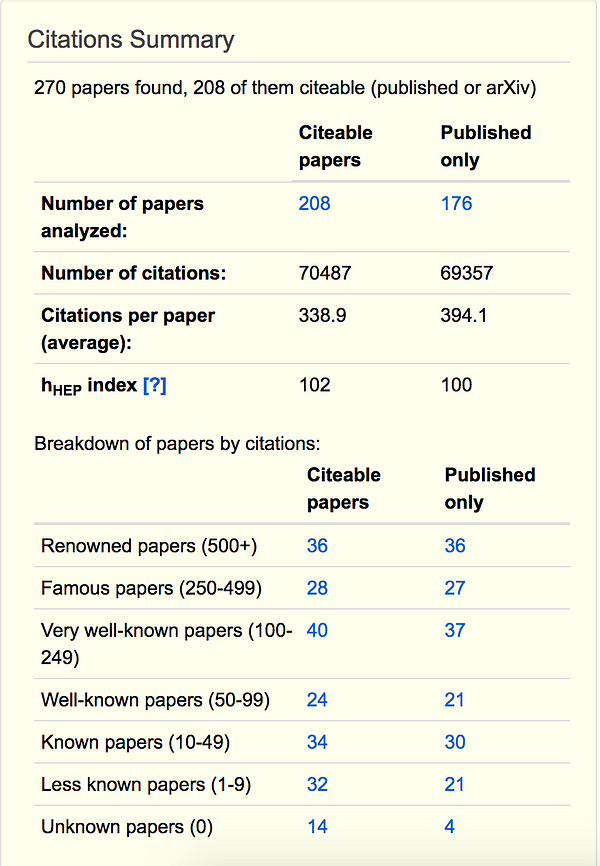
Citation
statistics summary for Steven Weinberg, Nobel Prize in Physics in 1979
for the formulation of the Standard Model of Particle Physics (along
with Glashow and Salam!).
Now,
Steven Weinberg has a whopping total of 70,487 citations, so if you
were to postulate that the scientific impact of a paper is proportional
to its citations, that certainly rings true in this case. However, this
paper, where Weinberg formulated the Standard Model of particle physics,
and which got him the Nobel Prize in 1979 along with Glashow and Salam,
is not the most cited paper in particle physics.
This
begs the question: is scientific impact best captured by the number of
citations? Citations are given a lot of weight, particularly in hiring
faculty or postdoctoral researchers. The issue is that you can think of a
few ways in which the system could be (not necessarily intentionally)
gamed, such as:
X cites Y and Y cites X back in return; or
X cites every one of X’s older papers whenever X writes a new paper; or
X
mostly writes papers about statistical flukes which get a lot of other
people excited, so X collects a lot of citations from those other
excitable beings by being the first to publish an explanation of what the fluke could be (before the fluke eventually goes away); and so on.
There
also seems to be that papers today have significantly more references
in them , so there is the possibility that newer papers are piling up
more citations than those in the past.
So,
with that context behind us, here are the preliminary results from a
side project where I quantify the impact of papers and of authors from
HEP using Google’s PageRank.
Note: while working on this project as a fun way to learn about networks, I came across this paper.
To my knowledge they are the first to use Google’s search algorithm to
gauge scientific papers. They focused on papers published on the
Physical Review journal from 1893–2003 or so. With that disclaimer
aside, the results that follow are my own.
Let
me, for clarity, briefly review how PageRank (PR) works through a
simple example. Suppose you have 3 websites, A, B, and C. We initially
assume that the total PR is equal to 1 and divided equally amongst all
websites, as each website is equally important. So, to start with, A, B,
and C, each have a PR of 1/3. Now, if for example B has a link to A and
C on its site, the PR of A or of C is: PR(A or of C) = 1/N + PR(B)/L(B), where
N here is the total number of sites, and L(B) is the total number of
sites linked by B. So now sites A and C are equally important, and more
so than B. In practice, you iterate several times until the PR of every
site converges to a steady value. I won’t write the general expression
for N sites, but in essence, each website endows its PR equally onto the
sites it links. What this algorithm is showing us is that sites
which are endorsed by others, which themselves are endorsed by many
others, are more important than sites that are not endorsed by others.
A technical bit: the algorithm also has another parameter called a
“damping factor”, which roughly corresponds to the probability that a
random user will click on one of the links of the current site. The
typical value one chooses is a damping factor = 0.85, which to my
knowledge is obtained from social experiments (see Wikipedia
article). I’ll comment on different choices of the damping factor at a
later date. Now, here I’ll make the connection website → publication,
and apply the PR algorithm to find papers that are “important”. Ok, now
onto the results.
Some Procedural Details
For this study, I downloaded the entire database from InspireHEP, which can be found here.
It’s available in several formats, and conveniently in JSON format, so
it’s very Python friendly. It contains the metadata of every paper from
~1962 and includes approximately 1.2 million publications to date. The
relevant information that it gives us for each record id (paper) is:
Authors;
References in the paper;
Citations to the paper; and
Publication date.
Now, this means that for every paper i we can create an “edge” (i,j) where j is a paper that i cites. Similarly, we can create edges of the form (k,i), where k is a paper that cites i. So, the collection of edges allows us to form a (directed) network.
You can find the code I’ve written and used for this project at my GitHub here.
Evaluating the Impact of Papers
So,
focusing on characterizing papers for now, you may ask what are the
papers with the highest PR on InspireHEP. The top-three are:
Steven
Weinberg’s Model of Leptons paper. It’s the paper that got him the
Nobel Prize. It has 10,709 citations to date, but it’s not the most cited paper on HEP.
2.
In second place we have Ken Wilson’s paper on the Confinement of
Quarks. It “only” has 4,483 citations to date, but its importance cannot
be overstated. Wilson is another Nobel Prize winner by the way,
although he did not win it for this particular paper.
3. Finally, in 3rd place, we have Kobayashi and Maskawa’s paper on charge parity violation. Another Nobel Prize winning paper.
For completeness, if you were going to rank papers by their number of citations, the top 3 would be:
Juan Maldacena’s paper on AdS/CFT. It basically started a whole new field. It’s been cited almost 13,000 times.
Maldacena’s paper on AdS/CFT. The top-cited paper on HEP.
2. Weinberg’s paper on “A Model of Leptons”.
3.
The Supernova Cosmology Project collaboration paper, where they
established that the Universe is expanding. This won Perlmutter a Nobel
Prize in 2011 (along with Schmidt and Riess).
The third most cited paper on HEP.
Ok,
that’s it for papers. Interestingly, while the highest cited papers
have definitely been impactful, a PR-based measure of impact does
capture something different than merely relying on citations does. In
particular, Wilson’s paper seems to be a huge outlier. I’ll look at this
and go into more detail about quantifying PR’s relationship to
citations and quantifying the impact of authors in the next post.





No comments:
Post a Comment