In order to improve the quality of systematic researches, various tools have been developed by well-known scientific institutes sporadically. Dr. Nader Ale Ebrahim has collected these sporadic tools under one roof in a collection named “Research Tool Box”. The toolbox contains over 720 tools so far, classified in 4 main categories: Literature-review, Writing a paper, Targeting suitable journals, as well as Enhancing visibility and impact factor.
Wednesday, 5 June 2019
Characterizing Scientific Impact with PageRank — Part II
This
is the second blog post in a series I’m writing documenting a side
project on characterizing scientific impact (you can find the part one here).
In particular, I think networks and graphs are very interesting. So as a
fun exercise I’m using PageRank (PR), the algorithm that Google uses to
rank websites in its search engine, to quantify the scientific impact
of papers and individual authors in High Energy Physics (HEP). In the
previous post I focused on papers. Here I’ll tell you more about gauging
the importance of individual authors, as well as the relationship
between PR and more standard metrics such as total number of citations.
Evaluating The Impact of Authors
Let’s
now focus on authors. The first question we must answer is how to
allocate a paper’s PR to its authors. You could choose to award that
paper’s PR to each one of its authors. While I haven’t chosen that
approach here, for completeness I computed authors’ impact using that
metric and found that the authors with the highest PR weight were mostly
those belonging to large experimental collaborations, such as the
general purpose experiments at the Large Hadron Collider, ATLAS and CMS.
These collaborations have thousands of physicists, and they put out
many (very good) physics analyses which get cited many times in turn. As
a rule, every member of the
collaboration has her/his name on each paper that the experiment puts
out. So perhaps this result is not too surprising.
What
I will do instead is to think of the PR of a paper as a prize, so it
should be divided equally amongst that paper’s authors. So if a paper
has N authors, each author gets awarded PR/N from that paper. Thus, for
each author in HEP, we can simply add up their total paper-derived PR in
this fashion. These are the physicists with the highest PR using the
entire HEP database info (you can read about the dataset on the first
post in this series):
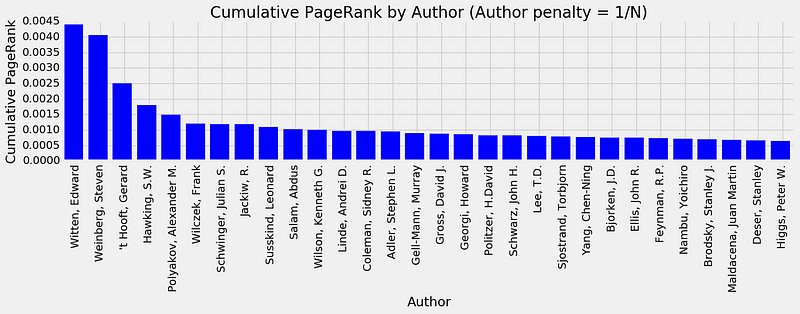
The
authors in High Energy Physics (HEP) with the highest PageRank (PR) as
awarded by the PR of the papers that they have (co-)authored. If a
publication has N authors, its PR is divided equally amongst the
scientists. There are 14 authors in the top 30 who have earned a Nobel
Prize in Physics.
So,
there we have it. The list is composed of some influential people. In
particular, about half of the top 30 authors are Nobel Prize winners.
And the other half is composed of some extremely famous people (without
naming names, many believe that a few of those who don’t have a Nobel
Prize in this list should have gotten one). Compare this to the
analogous distribution when we use total number of citations as a
measure:
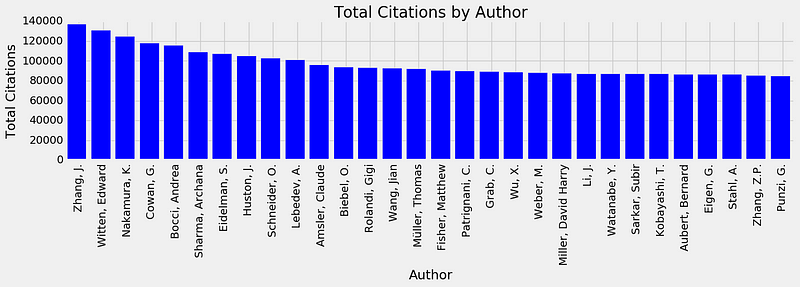
The authors in High Energy Physics (HEP) with the highest citation count.
Most
of the authors above belong to large experimental collaborations, as
discussed above, and I don’t recognize any Nobel Prize winners in this
list. What I’m trying to get at is that PR does capture something
different than just total citations would. You may ask about the case
where instead of assigning each author of a paper the total number of
citations, we do something analogous to the PR-assigning method I’m
employing, where we penalize by the number of authors. I tried that
approach too, and found that only around 20% of the authors in the top
30 were Nobel Prize winners.
PageRank and Citations Correlation
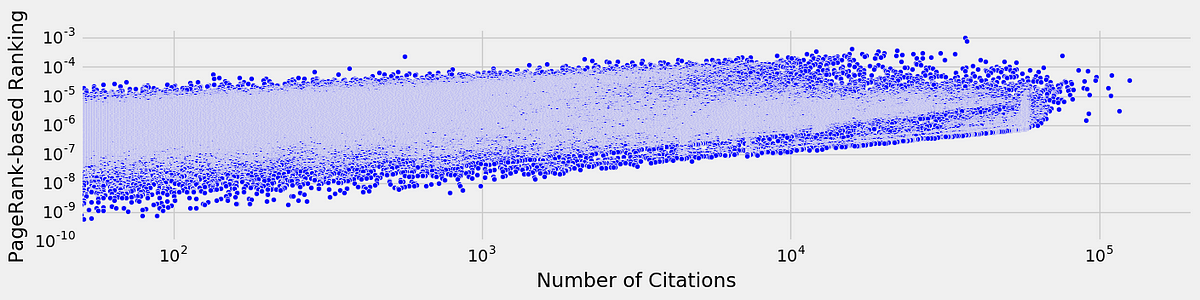
So, are PR and number of citations correlated? Let us quantify that for the case of authors.
From now on let’s select a narrower date range. In particular, let’s
focus on the network edges built from the papers published from January
1st 1997 until the present, where we award PR by dividing it equally
amongst the authors of a publication.
Scatter plot of the number of citations vs the PR of authors in HEP for papers published from 1997–2017.
Clearly
there is a positive correlation, but there seems to be a huge spread,
as the previous results had hinted. For completeness, let’s fit the data
to a straight line to ascertain what some of the biggest outliers are
with respect to the assumption of PR is proportional to number of citations N: PR(N) = a + bN, where a and b are coefficients that we find through linear regression.
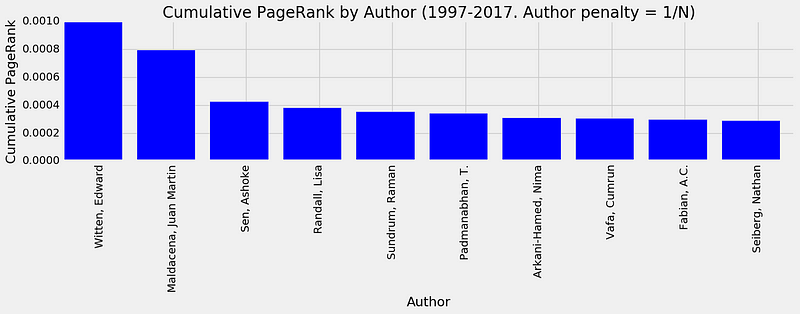
We
find that the biggest outliers under an assumption of linearity are
indeed the authors with the largest PR. Here are the top 10 outliers
(again for papers published in the last 20 years).
The
top 10 authors with the highest PR for papers published in HEP in the
last 20 years. They are also the biggest outliers under the hypothesis
that PR is proportional to the author’s total number of citations.
In
summary, we have seen that by using PR to quantify the impact of papers
and of authors, we are able to pick different features than we would if
we were relying on total citations. Interestingly, we can do a decent
job at identifying who a Nobel Prize winner is, by selecting the authors
with the highest PR when we studied the entirety of articles on
InspireHEP.
That’s it for now. In the near future, I’d like to focus on potential applications of this way of evaluating importance/impact:
So
far, we have done a very broad-brush characterization of a dataset
which spans a few decades’ time. Now, it’d be interesting if we can use
this method as a recommendation system. Suppose for example that
university X was conducting a search for a new faculty hire. Having had a
chance to serve on one such committee so far, people tend to rely
pretty heavily on citations, in addition to recommendation letters. So,
as a next step, let us see if we can recommend who the top candidates
would be in such a hypothetical search using PR as a measure, instead of
citations. I explore this through a simple example in the next post.
Beyond
PR and networks, can we identify an impactful publication at the time
it is published? Perhaps as step zero, we could proceed in a similar
manner as when building a spam filter, where we can construct our model
on a training sample consisting of the text of impactful papers.
No comments:
Post a Comment