Source: https://ieeexplore.ieee.org/abstract/document/9439531
A Bibliometric Statistical Analysis of the Fuzzy Inference System - based Classifiers

Introduction
Classification is one fundamental research task within developing the techniques of Data Mining and Artificial Intelligence. Since mapping the feature of a sample data to a set of category labels is the core task of classifiers, the Fuzzy Inference System (FIS) gradually attracted the researchers’ attention as a proven universal approximation [1]. Moreover, FIS-based classifiers have the advantages of extraordinary transparency and interpretability comprised of other famous structures such as Neural Network-based classifiers [2]. Therefore, FIS-based classifiers became an alternative structure for designing flexible classifiers, together with Bayesian classifiers, Decision Trees, Neural Network-based classifiers, and Support Vector Machines [3]. Nowadays, based on the above-mentioned excellent characteristics and the current outstanding performance of FIS, FIS-based classifiers are rapidly developing into one of the indispensable branches of high-performance classifiers.
Among the countless FIS-based classifiers, one vital band is the Evolvable FIS-based classifiers. These classifiers can be implemented in the structural form based on Neuro-Fuzzy or Fuzzy Rule. Evolvable FIS-based classifiers’ core advantages include organizing and updating their structure and parameters in real-time and online. Therefore, they were generally associated with data stream processing and approximated a dynamically changing environment [4]. These popular Evolvable FIS-based classifiers include, but are not limited to, the Evolving Takagi Sugeno systems (eTS) [5], [6], eTS+ [7], PANFIS [8], GENFIS [9]. Since uncertainty is an inherent fact in data stream classification, noisy measurement results and noisy data are different due to the expert’s knowledge. Whatever information technology, processing method, or other method is used, one reasonable solution is to utilize Type-2 FIS-based classifiers. The band of T2FIS-based classifiers is founded on Zadeh’s ideal (Type-2 Fuzzy Inference Systems) because it has the fuzzy memberships generated by a fuzzy-fuzzy set [10]. Conspicuously, the Interval Type-2 Fuzzy Logic Systems is one popular topic during the development of traditional T2FISs. It reduces the complex representation of traditional T2FIS. Therefore, parts of classifiers based on the Interval Type-2 Fuzzy Logic System have become prominent and widely employed [11]. For a long time, most of the above are developed based on TS-type FIS. AnYa-type FIS [12] was introduced as one alternative fundamental structure to the traditional FISs (Mamdani- and TS-type). Its advantages are free of parameters, logical connectors, aggregation operator, and membership functions in the Fuzzy Rule’s antecedent part. It is especially worth noting that the AnYa-type fuzzy system uses new data analysis techniques: its antecedent part (IF) relates the analyzed information to Data Cloud [13]. With the AnYa FIS-based classifier’s current research, its focus of classifying data streams is addressing high-dimensional, complex, or large-scale problems [14].
Until now, many researchers are still developing and improving FIS-based systems to implement FIS-based classifier modeling to cope with increasingly complex classification problems. Therefore, the number of FIS-based classifiers is not limited to the classifiers mentioned above. Therefore, before developing more in-depth research, new researchers will face severe challenges to determine research trends and model the entire research architecture of FIS-based classifiers. Fortunately, it seems that two powerful databases (Web of Science and SCOPUS) make it possible to overcome these difficulties. When using the databases, if researchers do not consider the particularity of the research topic, they will pay close attention to the number of citations and citation rate. These highly cited publications can help researchers find potential research fields or high-quality papers to evaluate the most cited publications in related research and successfully publish high-quality papers. Therefore, trend information is valuable and can speed up the research progress. Although neither citations nor citation rates are scientific information for evaluating publications, they can serve as practical guides and support for determining research topics. However, the databases often list too many related publications. We call this situation over-fitting. Such many publications usually involve too many research fields, including some areas that we want to ignore. Therefore, linking appropriate Keywords to search in the databases has become a challenge. Suppose here we already have a Keyword link to collect related publications. However, if a large number of results are listed in the databases, even if we are satisfied with the results, it will still force us to add more rules to limit the results so that they can be analyzed and processed within the time allowed. Therefore, the trade-off between coverage and reviewability is also a challenge. Under this pressure, the survey papers around research topics are like treasures, assisting us in promoting research progress. However, writing a traditional survey paper will take a long time, and it usually focuses on a small part of one research topic in depth. Therefore, exploring different survey methods to summarize and evaluate research topics is becoming a research problem. In the current situation, some studies have begun to notice the bibliographic information. The core guide is a statistical analysis of bibliometric information with their citation indexes, which can directly output the evaluation of other used articles’ quality. Therefore, the bibliometric analysis can help researchers understand specific publications and research fields and further promote more in-depth research on their literature.
With some early studies (such as social science [15], knowledge management [16], fuzzy research [17]) focused on analyzing bibliometric information, more and more researchers begin to focus on how to develop the analytical approach and utilize the approach to explore and evaluate the development of a research topic. The Bibliometric statistical analysis is defined as applying mathematical and statistical methods to analyze publications [18]. Hence, the analysis approach is developed to measure scientific progress as a standard research tool for systematic analysis [19]. This definition means that the approach can help researchers recognize research trends and evaluate scientific manuscripts [20]. In the current research cases, reference [21] used bibliometric analysis to study WoS’s m-learning publications. It provided readers with the commonly systematic statistical information to deepen their understanding. In reference [22], another bibliometric method was used to emphasize critical themes and various research trends. In particular, it used questionnaires to identify Keywords to collect related publications. It was also shown that peer-reviewed high-impact journals and academic databases could provide helpful and reliable research information. Reference [23] relied on a mixed-method, including bibliometric analysis and traditional review analysis, to complete quantitative and qualitative analysis. Although the above current research provided various bibliographic analysis methods, the low-quality trade-off between various bibliographic information and the lack of some critical bibliographic information is still apparent. Besides, because of the different focuses of their bibliographic statistical analysis approaches, it is difficult to determine which one is better than others. In particular, the research [23] may confuse us whether the bibliometric statistical analysis lacks research value, and the survey papers still have to rely on traditional survey approach to make up for its shortcomings.
In this research, a new systematic and time-saving bibliometric statistical analysis approach is proposed by extracting, integrating, and expanding the previous bibliometric theories. The new approach ensures the coverage of bibliometric information used to explore a research topic and makes a trade-offs between various bibliometric information. Meanwhile, this research adopts the proposed approach to determine the popular development trend of FIS-based classifiers. Also, the proposed approach extracts and summarizes the most relevant research information and resources that have a significant impact on the research topic (FIS-based Classifiers). Two well-known databases, WoS and SCOPUS, are used to extract all bibliometric information of FIS-based classifiers’ publications. WoS is a structured database that can index selected top publications, covering the most important scientific achievements. Although WoS is considered one of the largest and most trusted databases for literature search and analysis, SCOPUS journal reports seem more comprehensive than WoS [24]. Based on one extracted Keyword link, a total of 2,291 publications are collected from WoS and SCOPUS. The complete publication information will be used to analyze and evaluate our research topic comprehensively. The information covers document types, research fields most relevant to FIS-based classifiers, distribution of countries and regions, journals, authors, research fields, and Author Keywords. In addition, TOP 20 SETs summarize the high-impacted resources about FIS-based classifiers. Therefore, when we outline research trends and identify future research, this research analysis will contribute to the researcher’s concern. Meanwhile, this research will help researchers understand and determine the research field of FIS-based classifiers in an objective and credible approach.
The remaining parts of this paper are arranged as follows: The “METHODOLOGY” section introduces the whole proposed bibliometric statistical analysis method and follows the “LIMITATION” of this research. Then one merged “RESULTS & DISCUSSION” section (containing two sub-sections: Publication Information and TOP 20 SETs) provides intuitive data analysis results and comparisons. Finally, the “SUMMATION & FUTURES” section proposes a summary of the analysis results and points out the future works about the proposed approach.
Methodology
In order to overcome the above mentioned multiple shortcomings [16], [21]–[22][23], [25], this section introduces the proposed systematic and time-saving bibliometric statistical analysis approach. The research objectives of proposing the new approach include: 1) ensure the analytical balance and coverage of all key types of bibliometric data; 2) ensure simplified analysis methods and good analytical standards to promote preliminary research and exploration; 3) ensure that the method can output good results and provide high-quality features of a research topic. The proposed approach is from extracting, integrating, and expanding the previous bibliometric techniques. Its core is based on a quantitative analysis of all relevant publications collected by a Keyword link and searching in paper title. The above features make it possible to explore numerous publications without worrying about the analysis results’ insufficient quality. Furthermore, compared with traditional comment analysis, it has a high degree of flexibility in restricting and collecting publication resources. And, it can point out research trends and extract research resources with significant impact. Meanwhile, compared with the previous bibliometric statistical analysis, the proposed approach also make the analysis process more standardized and controllable, thereby greatly improving the robustness of the bibliometric analysis. These characteristics of the proposed approach ensure reliable analysis of research topic publications from different perspectives. Table 1 summarizes the comparison results between the proposed approach and the other latest bibliometric analysis method. For evaluating its performance, this research utilize the proposed approach to label the number, characteristics, and productivity of all publications related to “FIS-based classifiers”. At the same time, explore target areas to further determine possible research trends.

The proposed approach includes two parts, namely Data Collection and Data Analysis. In Data Collection, the process of defining the Query and collecting publications is described. Besides, it contains one direct evaluation method for evaluating the effectiveness of the collected publications. In Data Analysis, systematic and standard analysis methods will be introduced in detail for bibliometric analysis. The entire research process is shown in Figure 1.
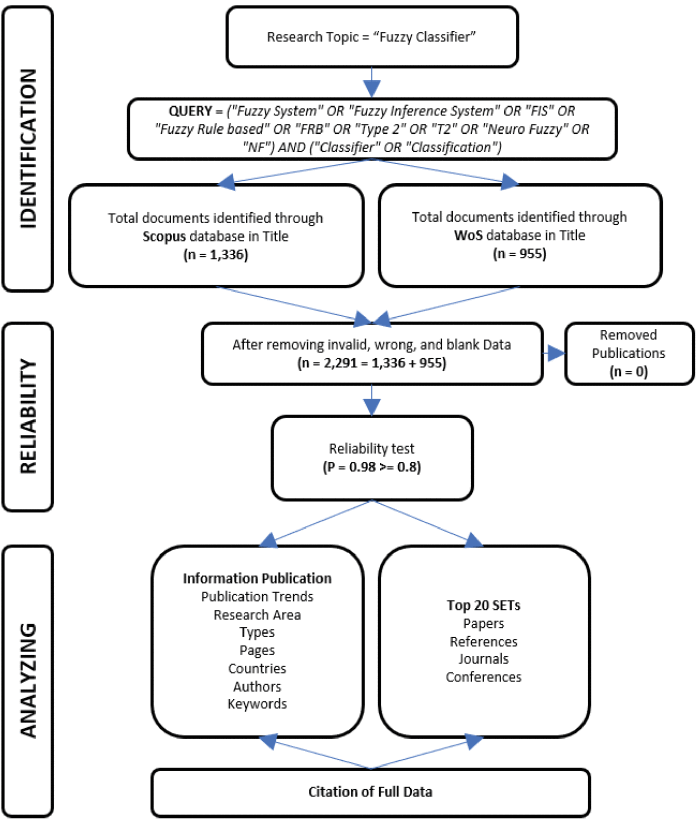
A. Data Collection
There are two databases used to collect whole relevant academic publications: Web of Science (WoS) and SCOPUS. Before preparing systematic bibliographic statistical analysis and comparisons, 50 high-cited articles are collected based on the research topic (“Fuzzy Classifier”) for defining the initial Query. Please note that the parameter “50 Highly Cited Articles” is not fixed. It depends on our expected search range. Research topics can also be directly used for searching and collecting, but will need to deal with various unpredictable and complex filtering and processing tasks. Even so, the proposed approach will still save a lot of time and effort. However, if there are few published papers on specific research topics, please consider using these research topics directly for collection. This research suggests that it is necessary to identify the search scope based on a research topic. After reading and discussion, the following Query is conducted for collecting whole relevant publications of fuzzy inference system used in classification: (“Fuzzy System” OR “Fuzzy Inference System” OR “FIS” OR “Fuzzy Rule based” OR “FRB” OR “Type 2” OR “T2” OR “Neuro Fuzzy” OR “NF”) AND (“Classifier” OR “Classification”). For exploring the whole research status related to the topic, the published date range is set by “before 2021”. The search options are set by “TITLE” in WoS and “Article Title” in SCOPUS. Here, TITLE options are limited owing to one important information that is what technique used for what research task in TITLE. Other settings include Science Citation Index Expanded (SCI), Social Science Citation Index (SSCI), Art & Humanities Citation Index (A&HCI), Conference Proceedings Citation Index (CPCI-S), and Emerging Sources Citation Index (ESCI) in the WoS Core Collection database. SCOPUS keeps the default options.
As a result, 2291 papers were collected, including 955 papers from WoS and 1,336 papers from SCOPUS. For comparing the different distribution characteristics of two databases in the research topics, this study only deleted these publications containing invalid, erroneous, and blank data releases and did not perform deduplication task by combining the two databases. The processed result shows that the original dataset quality is good, so that no publications will be deleted. Besides, the most important thing is about the file storage format before analyzing. WoS exports the original dataset in a “Plain Text” file format, and SCOPUS exports the original dataset in a standard “CSV” format. Notably, an additional merged dataset will be constructed in “xlsx” format when processing the removing task. They all need to contain the entire bibliometric information. The construction of these dataset files is a crucial step before further bibliometric statistical analysis.
The evaluation
task follows the collection task. Before conducting bibliometric
statistical analysis, evaluating the dataset collected from the two
databases is an essential step. This step ensures that our research is
focused on the exact research scope we expect. In this study, a simple
evaluation method is used directly. Ten articles were randomly selected
five times from all research publications. Everyone is carefully checked
to each article’s title and abstract to determine their eligibility
based on the inclusion and exclusion criteria mentioned above. One
publication that meets the bibliometric analysis requirements will be
marked as 1, while one publication that does not meet the requirements
will be marked as 0 [22].
Please note that no publication will be deleted in this step, even if
it is marked as ineligible. This step is only used to evaluate the
validity and reliability of these publications collected by Query. As a
result, the final average score is about 0.98 (
Here, all pre-processing tasks have been completed.
B. Data Analysis
In this study, all publications’ bibliometric information is collected for bibliometric statistical analysis. Three research tools (Microsoft Office Excel, VOSviewer, and R Studio) are used for achieving the analysis task. VOSviewer [26] is a software that can draw distance-based maps and clustering Keywords retrieved from the titles and abstracts of research documents [27]. The bibliometric software package in R Studio (an R tool for comprehensive scientific map analysis) [28] is designed for quantitative research in Scientometrics and Bibliometrics. The tool provides various routines to import bibliographic data from well-known databases such as SCOPUS and WoS [23]. The Microsoft Office Excel functions can conveniently perform statistics, analysis, and graphing on complete publications’ bibliometric information. In Result & Discussion part, all analyzing results are constructed by the above three software. Task distribution is introduced as the following two elements, namely data visibility and data processing.
In data visibility, 1) using Microsoft Excel to produce the following: the trend of Publications, average citation, the ranks of research areas, a quality comparison among research areas, the distribution of publications types, the statistic information of publications pages with evaluation, the box plots analysis of publication pages, the statistic information and distribution of the global publication, a distribution map of global research hotspots, the distribution of publications and citation with authors, Statistical information of most-cited Author Keywords, the box plots analysis of reference number, the statistics of references with evaluation, and all tables of statistical analysis; 2) using VOSviewer to produce the following: The relationship among Author Keywords in WoS and SCOPUS, Density Clustering of Author Keywords in WoS and SCOPUS; 3) using R Studio to produce the following: Top Authors’ research activities over time, the trend of top-20 popular Author Keywords over time, the trend of top-20 famous journals of WoS and SCOPUS. However, for achieving TOP20 SETs, combining R Studio and Excel is one necessary step.
In data processing, the following will introduce the average citation rate of publications (APC), the average resource citation rate per year (ACPY), the average citation rate of a single item in all resources per year (AAPY), and the average global value of AAPY, namely FAPY. These formulas are listed below in detail:
Besides, a mathematical tool, Box Plot (Figure 2), is used to display scattered data. The tool was invented in 1977 by the famous American statistician John Tukey. And it is a standardized data set to display based on Minimum observation, Maximum observation, Median, The first quartile, and The third quartile. An additional element is an interquartile range or IQR (Interquartile Range), representing the distance between the upper quartile and the lower quartile. Therefore, the tool is used to find the appropriate interval as a reference and can also be easily used to visually summarize and compare data sets [29]. In various fields, often be used in quality management.
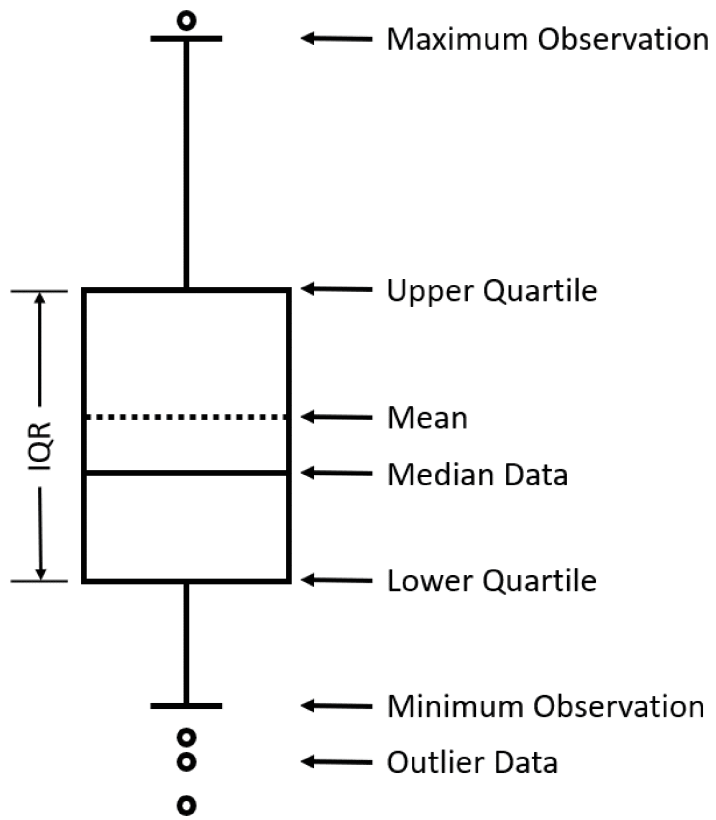
Here, all data analysis processes have been introduced.
Limitation
Although this study utilizes one convincing Query to collect full publications from two well-known databases, this method may force other researchers with insufficient knowledge of his research topic or do not understand any bibliometric analysis methods to spend more time discussing the necessary high-cited papers for conducting Query. Some papers could provide different methods for expanding keywords to obtain one sufficiently convincing Query for collecting publications, such as [16], [21]–[22][23], [25]. In addition to the statistics and analysis of the necessary bibliometric information of publications, although this study expands the range of the top-ranked collections from the top 10 in regular numbers to the Top 20, they still cannot stand for the research topic of FIS-based classifiers. Meanwhile, Query’s keywords maybe not have covered the entire research topic, impacting the results. As same as [30], visibility may be an essential factor in increasing the citation number. However, this research mainly focuses on citation as an essential quality indicator and publication goal to explore the relationship between bibliometric information and citation.
Results and Discussion
This section is divided into two sub-sections. The first shows the statistics and influence of various published bibliometrics information. In most cases, the top 20 influential resources will be selected and displayed. The second Sub-section, TOP 20 SETs, shows the actual various resources related to TOP information. These results enable researchers to have a systematic and basic understanding of the publications released for FIS-based classifiers.
A. Publication Information
As previous research [30] indicated, the number of publication citations was one key factor in evaluating publication quality. This sub-section will closely combine publication citation with various aspects of bibliometric information, such as the number of publications per year, the number of publications in each country, the number of authors and their trend, a statistic of Author Keywords, the number of publication pages. These processes will deeply explore the relationship between publications’ information and citation.
1) Publication and Citation
Since the first paper was published in 1952, no more than 2 papers have been published every year until 1995. From the beginning of 1995 to 2000, there was the first growing trend. SCOPUS publications increased from 6 to 20, and WoS publications increased to 18. In 2000, 23 publications in SCOPUS and 18 publications in WoS reached their first peak. Then came the trough in 2001. Fortunately, since 2002, the number of papers has snowballed. When the second peak occurred in 2010, this growth trend stopped. In that year, SCOPUS published 75 publications, and WoS published 46 publications. Although there were 56 publications of SCOPUS and 27 publications of WoS in 2011, the trend reached its lowest point in 2011. However, from 2011 to 2020, this trend was growing at an alarming rate. Then, the publishing trend achieved its third high growth. The WoS peaked in 2016 with 82 publications, and the SCOPUS peaked in 2019 with 104 publications. Therefore, one situation is noticed: the peaks of WoS and SCOPUS occurred in different years. However, according to the WoS trend, the number of publications dropped significantly after this peak. It shows, the number of FIS-based classifiers was decreasing since 2018. The main trend is shown in Figure 3. Although the figure illustrates a promising trend between 1990 and 2020, the part of these publications are cited. In all publications based on FIS-based classifiers, only 690 out of 955 samples were cited, and 1080 out of 1336 samples were cited. They are accounted for 72.25% and 80.84% of the total dataset, respectively.
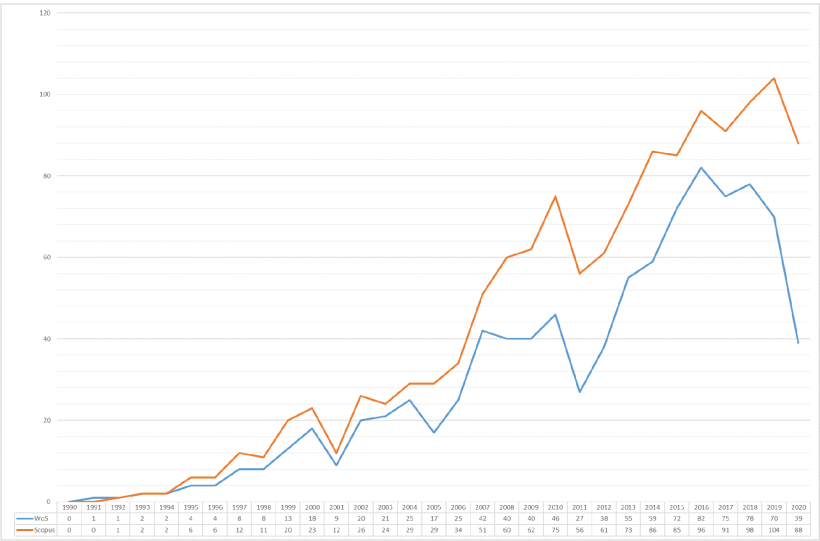
The following is a brief overview of the trends mentioned above. Since 1952, the FIS-based classifiers’ concept has appeared in publications, and trends indicate that the topic has become more and more popular in the 20 years from 1998 to 2020. This release trend may be owing to more and more practical applications in Data Mining and Intelligent Systems. The period may have promoted discussion and research on the relationship between computers and other fields. Although the trend contains two valleys, the citation rate of these publications is high. Until 2020, many new publications’ highest quality does still not exceed the highest level after 2001. The feature is shown in Figure 4. Besides, in recent years, the interaction between computers and humans, artificial intelligence, and data mining attract more attention. Fuzzy reasoning systems are usually developed as intelligent systems and powerful data mining tools. Between 2018 and 2020, the number of publications has dropped significantly. Since this downward trend is evident at the end of the study, it is difficult to determine whether the decline in the number of FIS-based classifiers is temporary or the topic has begun to show a long-term downward trend. Usually, this situation can be ignored owing to insufficient statistical information.

Besides, to explore the potential impact of the citation trend, ACPY is used for evaluation without directly calculating the citation rate trends. As shown in Figure 4, based on all database publications, the quality trends seem to have been increasing between 1952 and 2020, and their dynamic trends are so close. Please note that the dramatic situation that is the peak of ACPY occurred during the entire development process in 2001, but the same year’s circulation was at a low point. This situation may indicate that our research should focus on these articles published in 2001 (9 in WoS, 12 in SCOPUS). Similar to the publishing trend, since the last year of the record is 2020, it is not clear whether the ACPY value of FIS-based classifier publications will continue to decline, or the topic will start to increase. However, the SCOPUS of these trends has been dramatically reduced. The two evaluation lines of the two databases are also displayed in the same graph, which indicates that the future growth trend is positive for FIS-based classifiers’ research.
2) Research Areas or Subjects
The research topic of FIS-based classifiers involves many fields such as Education, Mathematics, Engineering, Robotics. To better explore the research and publication fields of FIS-based classifiers, Figure 5 collects and lists the top 20 research fields that account for most of the entire publication. Among these fields, Computer Science, Engineering, and Mathematics are the most studied fields in the entire research field. According to the highest number of cited papers in each database, more research has been conducted in these research fields. Computer Science has the most significant number of publications, and its top 20 publications and top 200 publications also rank first.
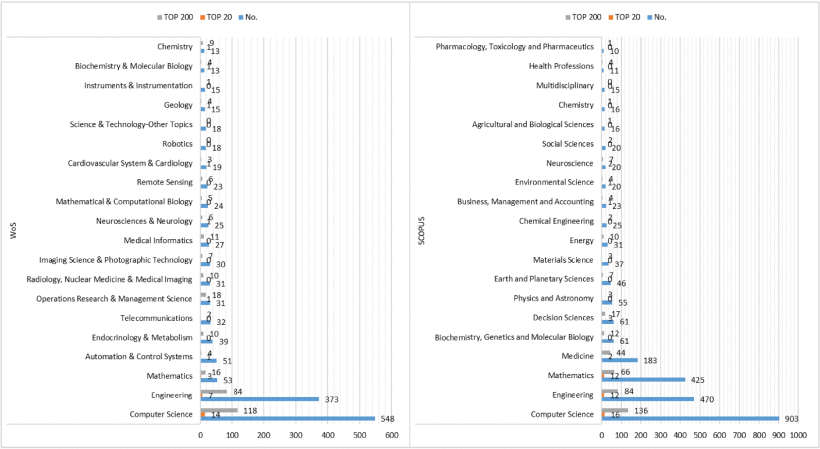
On the other hand, Figure 6 shows one negative result by analyzing their distribution in all research fields. Regardless of the distribution of the top-20 or the top-200, Mathematics, Operations Research & Management Sciences, Neuroscience & Neurology, Geology, Biochemistry & Molecular Biology, and Chemistry research area show better quality publications than Computer Science in WoS. In SCOPUS database, Engineering, Decision Sciences, Business, Management and Accounting, Environmental Science, and Neuroscience research area show better quality than Computer Science. The above situation seems to indicate the following conclusions. Although the amount of research on FIS-based classifiers in computer science is the largest among other research fields, its research progress is still brewing. In short, the subject of computer science research is no more mature than other fields. If analyzed from a philosophical point of view, FIS-based classifiers still have incredible potential because a change in quantity will lead to a change in quality, and a change in quality will lead to a new quantity change, namely the Law of Interchange of Quality and Quantity.

3) Types of Publications
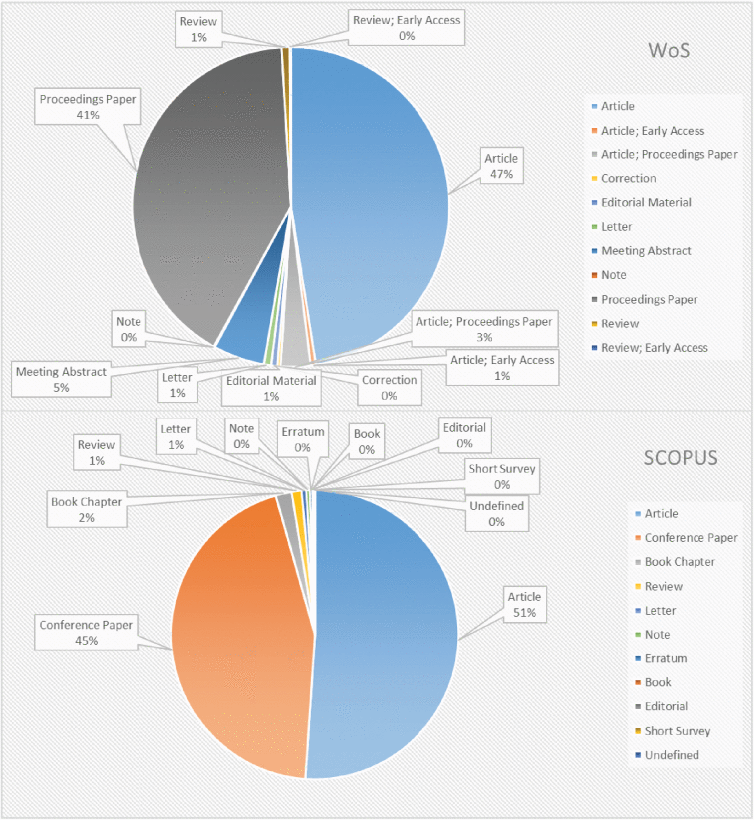
Figure 7 illustrates the distribution of the primary document types of the two databases. Among all publication groups, articles (47%) and conference papers (41%) are the main contributors to WoS, while SCOPUS has about 51% articles and 45% conference papers. Besides, the research found that English is the primary language and has nothing to do with meetings, articles, or other formats. Another auxiliary output of document types in all publications is editorial material, reviews, conference abstracts, news, book reviews, letters, corrections, chapters in the book, articles about individuals, and reprints. In summary, even if paper and articles are the most commonly used document types, others highly dispersed document types should not be ignored because these numerous document types may have their inherent value and meaning. If we conduct further research, we may provide some unique insights into research trends. The important thing is that, as shown in the drag graph, the research topic of FIS-based classifiers has excellent potential owing to the high distribution of conference papers. Generally, the conference has the following advantages: the short feedback time, contains the latest work completed so far, and can interact with international audiences working in the same field. Therefore, in addition to mainly focusing on articles, it is necessary to focus on conference publications.
4) Pages of Publications
For investigating whether one relationship existed between the number of pages and their citations, this part is to explore by using the information of Figure 8. After statistical calculation, in WoS, its results show that the maximum number of pages is 56, 1 is for minimum pages, and 9.16 is for the average number of pages. Meanwhile, the maximum number of pages for a full FIS-based classifier publication of SCOPUS is 226, the minimum page is 1, and the average number of pages is 13.65.

To further explore, APC, AAPC, and FAPC are used to determine whether there is a positive or negative relationship between page number and citation rate. If AAPC (Greyline in Figure 8) is over FAPC (Yellow line), these publications can be labeled as the positive cited rate. As the figure has shown, the number of pages of a high-quality WoS publication is usually between 7 and 16. Limiting the number of our publications to this range may be necessary. Besides, due to the insufficient number of publications, some high-quality publications with 25, 31, and 33 pages may be ignored. Meanwhile, in SCOPUS, the issuance interval of highly cited publications is between 7 and 17 pages. Besides, the impact of a one-page publication is excellent in SCOPUS. Of these one-page publications, conferences accounted for 66%, articles accounted for 28.71%, with errata, letters, notes, and comments accounted for the rest. In WoS and SCOPUS, 6-page publications with numerous publications and low citation rates are very abnormal. These publications contain 83% meetings and 17% articles in WoS, 74% meetings and 26% articles in SCOPUS. Perhaps the 6-page situation is one fixed requirement from publishers, forcing researchers to limit their published pages to 6 pages. Therefore, the research results indicate that please make sure that the number of pages in the publication is not 6. May one thing can be ignored that is having confidence in the quality of the publication.
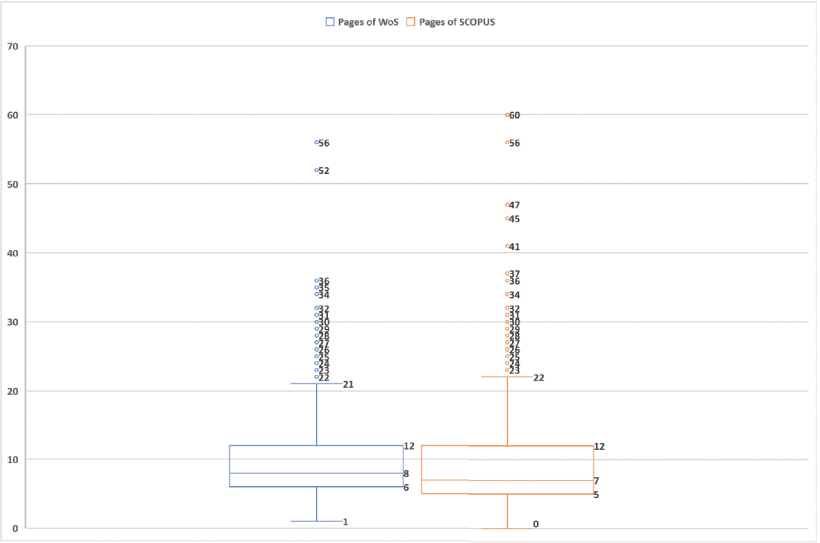
Besides, Box Plot is used for assessing one appropriate interval of the number of pages. As shown in Figure 9, in the complete publication of SCOPUS, the lowest score, lowest quartile, median, highest quartile, and highest score for the number of published pages are 1, 5, 7, 12, 22. In WoS, they are 1, 6, 8, 12, and 21, respectively. Therefore, generally speaking, in the research field of FIS-based classifiers, it is better than the pages we published are between 6 and 12. Besides, as shown in Figure 8, although there is no precisely significant relationship between pages and the number of citations in FIS-based classifier publications, this study found that the recommended number of pages for fluent publishing and the best citation rate remained between 7 and 12.
5) Countries or Regions
Table 2 lists the 20 most active countries/regions in the FIS-based classifier. The sum of these countries’ publications is estimated to reach 95.71% of WoS and 78.50% of SCOPUS in full papers. In the 20 most active countries, India, Spain, and the USA have the most active research status. To better understand the quality and impact of FIS-based classifier articles in each country/region, the number of publications, citations, and the percentage of the top 20 countries/regions with their citations are also displayed. Relying on the two databases’ different features, this part also summarize WoS citation information and illustrate SCOPUS distribution. Therefore, a statistical table and a distribution map based on the two databases are generated.
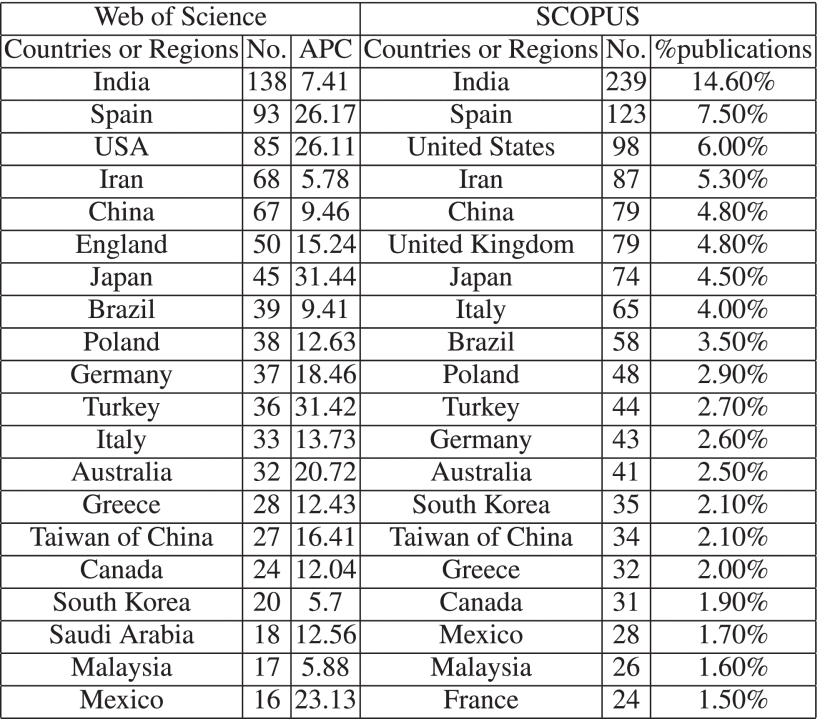
As shown in Table 2, although Japan ranks seventh in the total number of published articles, its APC is the highest with approximately 31.44. This situation means that the quality of papers published in Japan is the highest in the research domain of FIS-based classifiers. Other countries with high-quality publications include Turkey, Spain, the United States, Mexico. Comparing with previous countries, India has the most publications and citations, and the APC value for all articles is only 7.41.
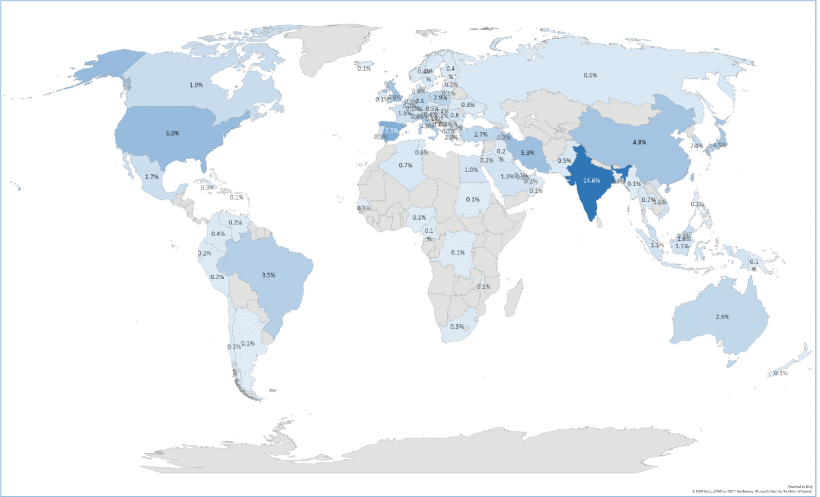
According to the following world map (Figure 10). It is possible to determine which regions have published an analysis of the most articles on the research topic. As the world map clearly shows, most of the research are from Asia, North and South America, and Europe. As one summary, this research topic (FIS-based Classifiers) is more prevalent in Asia and North America.
6) Authors of Publications
After surveying all authors performance in WoS and SCOPUS databases, there are 3,463 authors in WoS, with an average value 3.63 for every paper, and 4,554 authors in SCOPUS, with an average value 3.41 per paper. The situation means that each paper may generally have more than three authors in the research domain of FIS-based classifier.
Besides, Figure 11 explores the most popular authors’ research activities, containing 19 authors of WoS and 20 authors of SCOPUS. The results indicate that, although some authors have published many papers before, there are few studies in recent years, such as Herrera, F. Ishibuchi, H. Nakashima, T. Del Jesus, M.J. On the other hand, other’ researcher activities have been active in the past five years, such as Bustince H, Konar A, Melin P, and Sanz, JA. Therefore, if we want to understand the current popular research topics, paying more attention to them is a valuable option to start understanding the field of FIS-based classifiers.
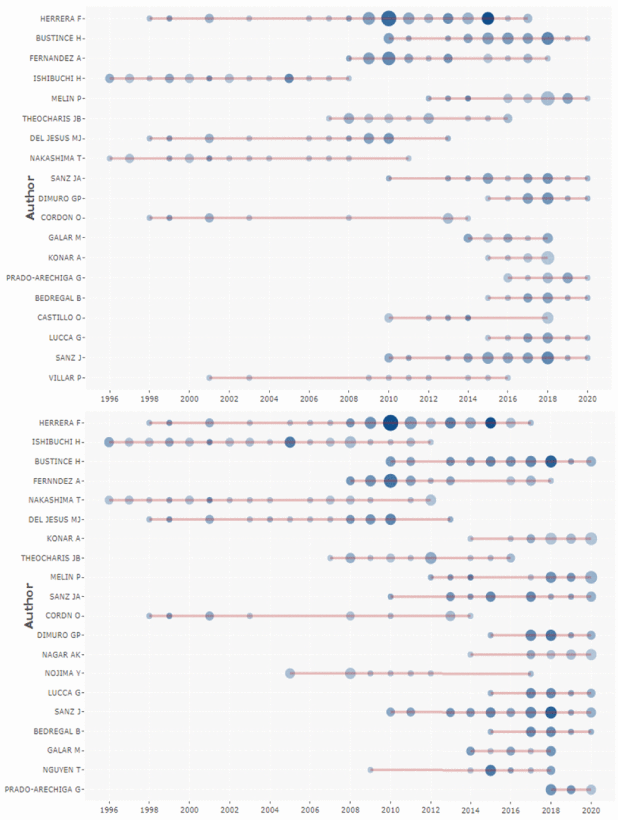
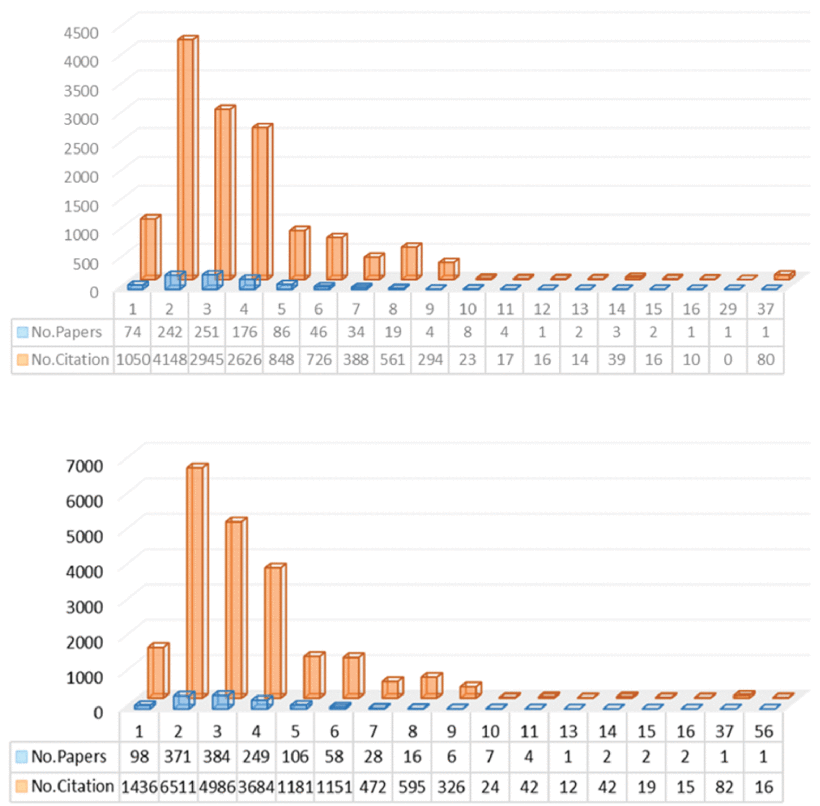
Also, to explore the relationship between authors, publications, and citations, Figure 12 was generated for this purpose based on WoS and SCOPUS. According to their performance, their distribution is very similar, and a noticeable feature is that most publications have 2, 3, or 4 authors, and their publications are beautiful. Articles with one or four authors are also cited at a high rate, but publications with five or more authors are less likely to be cited. Besides, although papers co-authored by 37 authors have received widespread attention, this situation does not represent an expected feature in the field of FIS-based classifier research. These results mean that usually choosing 1 to 3 partners is the right choice to advance our research. Please notice that some special publication focusing on their research quality needs to ignore the statistical guideline.
7) Author Keywords
From a researcher’s perspective, Author Keywords are essential types of information about research trends and have been proven to be of great significance for monitoring scientific development [31]–[32][33]. Besides, Author Keywords usually contain the researcher’s primary research goals and solutions. Therefore, this section will analyze Author Keywords from three different perspectives. The first focus is to perform statistical analysis on the Author Keywords and citations to identify popular keywords. The second focus is to show their popularity and quantity. The third focus is to cluster them to help researchers expand relationship groups according to different kernel Keywords.
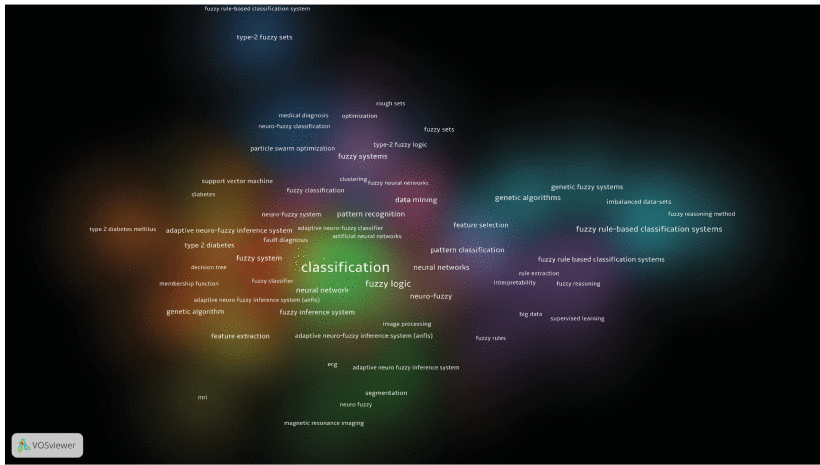
As the research continues, the Keywords will continually change over time. Therefore, Figure 13 and Figure 14 explore the hidden changes in Keywords over time and their relationship networks. Their circle’s size indicates popularity, and a higher score (Yellow) indicates that the Author Keyword is close to 2020. As shown in the two figures, we can quickly obtain current Keywords to guide our research. Meanwhile, this study primarily cluster these Keywords based on different databases to help researchers further understand the FIS-based classifier field and the relationship between different Author Keywords. The results are shown in Figure 15 and Figure 16. The expression of clusters with different colors and the close relationship between groups can help us understand the relationship between Keywords more deeply. For example, combining Figure 13 and Figure 15, we noticed the keyword “big data” at the bottom right of the pictures. The following research topics surrounding big data are fuzzy rules, fuzzy reasoning, rule extraction, supervised learning, and interpretability when observing its cluster. These Keywords have paramount significance in the further research of big data. However, do not forget to do the horizontal comparative analysis after the above longitudinal comparative analysis. For example, take “big data” go into Figure 14 and Figure 16 for exploring more relevant Keyword network. That is one critical reason why this research does not integrate two databases’ data. Therefore, when conducting research, we will not let keywords limit our thinking to a certain extent.

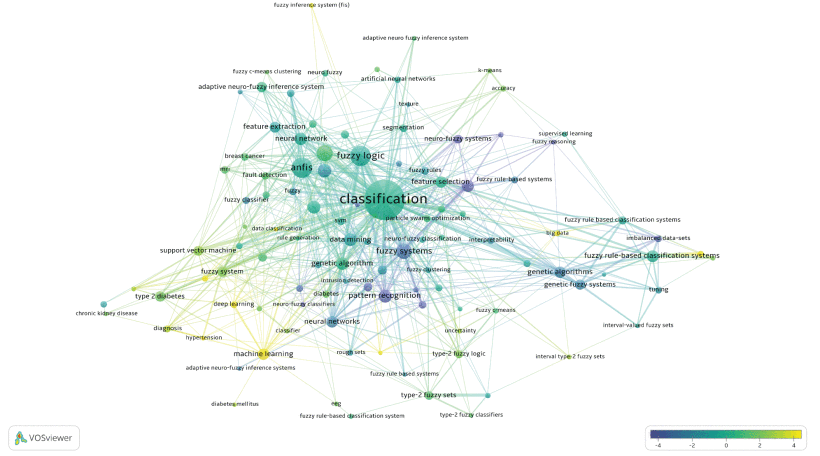

Meanwhile, Figures 17 shows the top 20 most commonly used Author Keywords’ statistical results and their citations from the WoS and SCOPUS databases. Its lift side (WoS) shows that the most popular keywords are classification, fuzzy rule-based classification system, pattern classification, fuzzy rule-based system, fuzzy logic, fuzzy system, genetic algorithm, pattern recognition. Simultaneously, its right side shows these Author Keywords in SCOPUS, including classification, a classification system based on fuzzy rules, pattern classification, fuzzy logic, pattern recognition, neural network, ANFIS, data mining, neuro-fuzzy. Besides, Figure 18 investigates the development trends of these keywords over time. Most of them maintain a stable growth rate. The situation also shows that the topic has potential development capabilities, especially under the current competitive solid pressure from other classifiers.
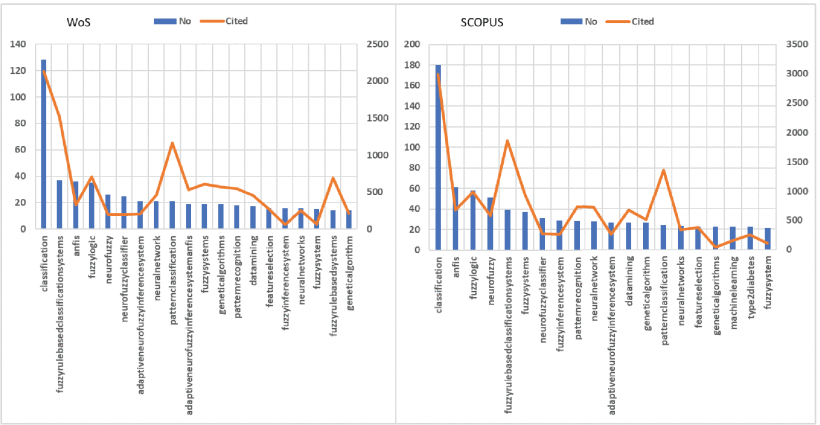

B. Top 20 SETs
The sub-section of Top 20 Sets consists of four parts, including the Top 20 of most-popular publications, the Top 20 most cited references in the whole publications, the Top 20 most-popular resources, and the Top 20 popular conferences. And their statistics information will be discussed.
1) Top 20 Publications
Table 3 lists the Top 20 most-cited and -popular publications in this part. The TOP 20 most-cited publications’ citation account for more than 27.29% of the total citations in WoS. However, their publication number only account for 2.09% of the 955 publications, and these publications were published between 1995 and 2015. In SCOPUS, the Top 20 most-cited publications’ citation account for more than 21.95%. They were published during the same period as WoS and their publication number account for 1.496% of the 1,336 publications. Besides the above, Table 3 also identifies the Top 20 most-popular (High ACPY) publications in each database. If the average number of citations per year is high, the publications are considered popular. Furthermore, the entire top 20 most-cited publications were published between 1995 and 2015, and the entire top 20 most-popular publications were published between 1997 and 2019. Not surprisingly, there is much overlap between the two databases. The percentage is 85% in the Top 20 cited, and 80% in Top 20 popular.

In the TOP 20 table, the best quality publication research on Neuro-Fuzzy Inference System, and two high-impact review papers focus on surveying Type-2 Fuzzy. Besides, the table lists ten publications in the top 20 most-cited and most-popular lists simultaneously appearing in each database. Therefore, relying on the TOP 20 table, many key research knowledge can be easily obtained, such as the most popular FIS structures, the popular research questions, and the practical application of FIS-based classifiers. This is an important step in constructing a knowledge graph of FIS-based classifiers.
2) Top 20 References
In this part, comparing the references citation and the references number is a significant task. Through statistical analysis and an evaluation of the citation number, any connection between citations and reference number can be determined. This has been illustrated in Figure 19. According to the comparison results, there seems to be no exact correlation between the number of references and the number of citations. However, by comparing and evaluating their interval window’s different sizes in each database, two significant intervals are detected. There is a high probability that high-quality publications are produced in the two reference intervals. WoS indicate the reference interval is between No.38 and No.59 (Horizontal Axis), while SCOPUS indicates its interval is between No.40 and No.59 (Horizontal Axis). The two intervals are remarkably similar. Besides, trends in other intervals cannot provide more valuable results.

Besides the above finding, this part uses Box plots to explore a distribution of the references number in complete publications. The results are shown in Figure 20. The number of references on this topic in FIS-based classifier publications is usually between 13 and 35 in WoS and between 15 and 36 in SCOPUS. The interval between the two is also similar. However, if the two reference intervals are evaluated using Figure 19, their quality performance on producing high-quality publications cannot be achieved within the expected high-quality interval of Figure 19. The reason is that the reference intervals obtained from the Box Plots and AAPC assessment are completely different. If the results are combined with other analyses of this study, it can be proved once again that this situation may be due to the immature research topic and too many publications.

Most importantly, under the above pressure, in order to promote the development of the research topic (FIS-based Classifiers), this research makes the proposed bibliometric statistical analysis method contain the function of extracting TOP references. Therefore, listing the top 20 most frequently cited references in Table 4 is a necessary step for the TOP 20 SET due to these references are the basis of the research topic. As shown in the table, most of them were released between 1992 and 2005. Unexpectedly, the most-cited reference also study Neuro-Fuzzy.
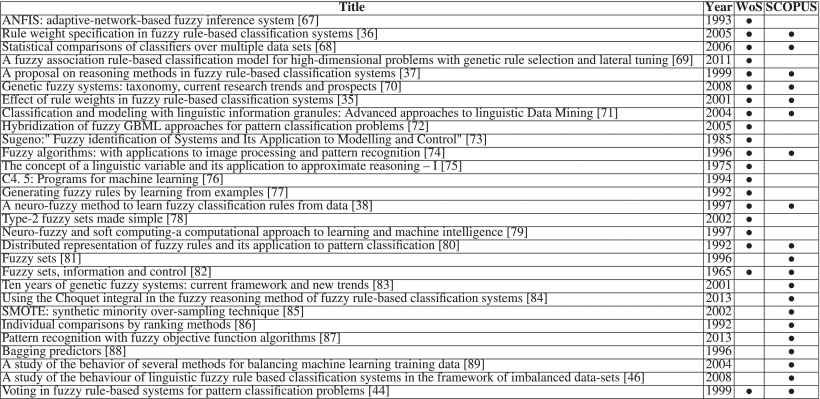
3) Top 20 Resources
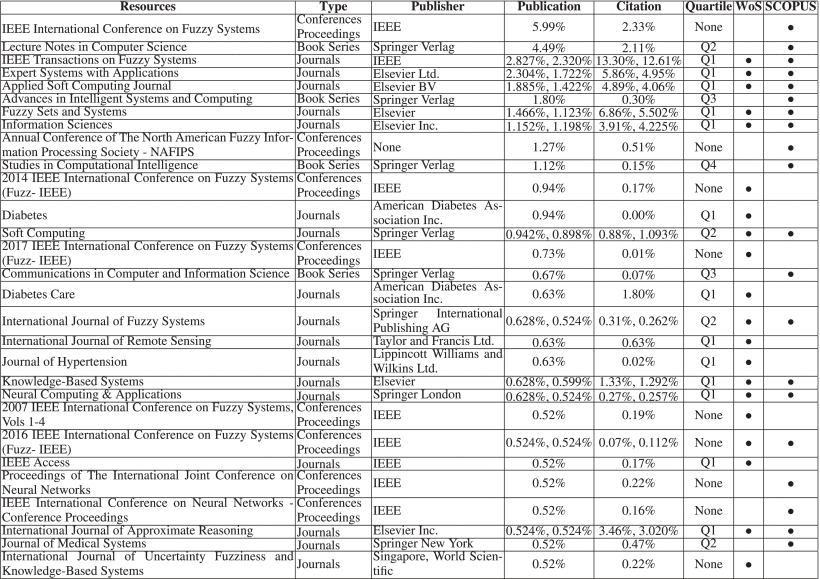
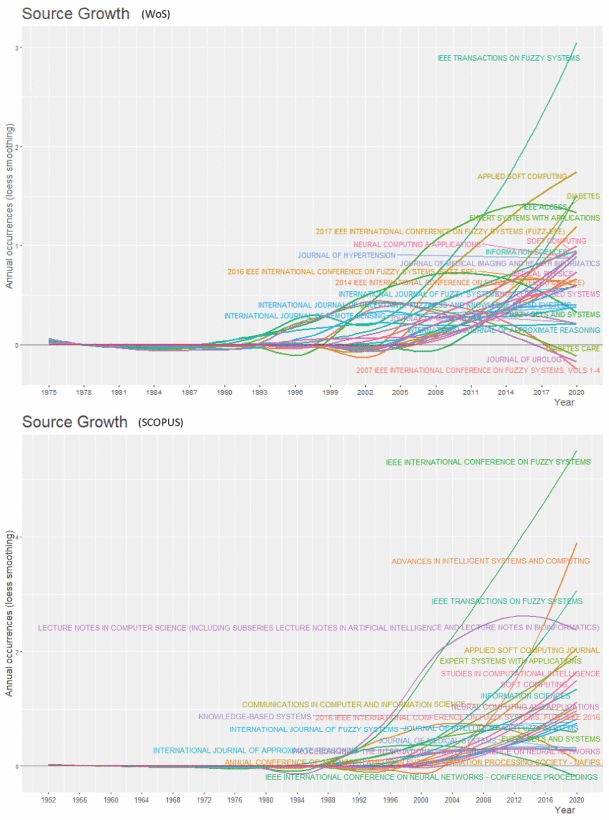
Here, for determining whether there is a relationship between published journals & conferences and citation frequency, this part will analyze resources issued by publishers based on the number of published journals & conferences with the citation number. Table 5 shows that the publications of top 20 resources account for 19.581% of all the publications and their citation account for 44.53% of the citations’ total number. Strangely, the publications issued by Diabetes Journal seem not to be cited by other publications, even though the total number of publications ranks 12th with a rate of 0.94%. However, the quality level of Diabetes belongs to the Q1. We should note that the subject of FIS-based classifiers in Diabetes domain may take some time to develop, or in fact these publications have great potential but have not attracted researchers’ attention. For further assessing the entire resources quality, the validity between publication and citation can be evaluated by only calculating the value of (%Citation/%Publication). The results show that the most effective level is the International Journal of Approximate Reasoning, IEEE Transactions on Fuzzy Systems, Fuzzy Sets and Systems, Information Science. Since the publications come from WoS, the quality of these publishers is high. In this case, it is necessary to analyze the data sheet SCOPUS, which contains complete release information. These statistic information are also listed in the same table. The top 20 publishers of SCOPUS accounted for 28.293% of all the publications and 43.687% of the citations’ total number. Generally, researchers can cite any of these 20 publishers to attract high attention. In the top 20 list, there is only one Q4 publisher with ranking 10th and 0.151% citations, namely Studies in Computational Intelligence. In addition, this research survey the dynamic tends of these resources in Figure 21. As one obvious result, such as IEEE Transactions on Fuzzy Systems, Applied Soft Computing Journal, Diabetes, IEEE Access, Advances in Intelligent Systems and Computing, IEEE International Conference on Fuzzy Systems, these resources have an unbelievable growth trend. Therefore, for obtaining high quality publications, we should pay more attention to them in future research.
4) Top 20 Conferences
As the publication type in “Type of Publications” part proves, their number of the conference type publications and the proportion of articles based on FIS-based classifier research are almost the same. Therefore, this part uses Table 6 to list the top 20 conferences in WoS and SCOPUS. As shown that, the sum of the top 20 citation rate of papers published at these conferences is incredibly the highest than other types of publications, and the sum of publications also is the highest, including 13 conferences from WoS and 14 conferences from SCOPUS, and 6 conferences simultaneously collected by both of databases. Meanwhile, more conference papers mean that the research topics of FIS-based classifiers still have excellent potential. Therefore, these conference publications are rapidly promoting the development of the FIS-based Classifiers.

Summation and Futures
Due to the lack of standard bibliometric analysis methods and the confusion between bibliometric analysis and traditional literature reviews, a new bibliometric approach is proposed to fill the research gap. This research makes the proposed bibliometric statistical analysis more systematic, standard, and time-saving. The feature, systematic, means that the analysis results have better coverage and trade-off the various bibliometric information against the preferred information without paying too much attention to the preference Information. The feature, standard, means that the proposed bibliometric statistical analysis consists of two parts: Publications Information and TOP 20 SETs. Meanwhile, to achieve the analysis task and ensure analysis results’ quality, this research named several formulas (APC, ACPY, AAPY, FAPY) and used a mathematical tool (Box plots). At the same time, the proposed approach ensures the validity and reliability of the result features. The time-saving feature means that even if the analysis object has a large amount of data, these analysis methods will not significantly increase the analysis process’s complexity and will not lose the result characteristics’ quality. These features mentioned above enable the proposed method to analyze numerous publications while ensuring the quality of analysis.
This research significantly improved the fuzzy inference system-based classifiers’ overall understanding in one unprecedented approach owing to adopting the proposed bibliometric statistical analysis method. In the beginning, relying on the research topic keywords “Fuzzy Classifier”, one extracted Keyword Link is used to collect all relevant publications before 2021 from the Web of Science (WoS) core resource library and SCOPUS. After searching in TITLE, 955 publications are collected from WoS, and 1336 publications are collected from SCOPUS. These WoS publications were assigned into 89 research areas (only one publication in each of many research fields) and 11 different document types. In SCOPUS, 1,336 publications were distributed into 26 research areas and 11 different document types. English accounts for the primary language. These publications indicated that focusing on Computer Science, Engineering, and Mathematics bears the primary responsibility for promoting the research topic’s development. From the distribution analysis globally, this research topic has attracted more and more attention in India, Spain, the USA, Iran, and China. These countries play a pivotal role. However, in Japan, Turkey, Spain, the United States, Australia, and Mexico, their quality is higher than in other counties. Analyzing all authors shows that a respectively average of 3.62 and 3.41 authors per publication. Most publications are published by 2 to 4 authors. Therefore, typically finding 1 to 3 partners can promote new research and increase publications’ citation rate. At the same time, this study lists the top 20 most-publication authors. Investigating the trends in research activities of 19 WoS authors and 20 SCOPUS authors is necessary to explore the development trends of research topics further.
Author Keywords usually contain the author’s subjective essential research tasks. Analyzing them is an essential step in determining research categories and trends. In this study, the analysis task is divided into three different perspectives: traditional statistical analysis, visualization of time series trends, and clustering of the relationship density between author keywords. Relying on these analyses and processing, we can easily extract current popular keywords to expand and evaluate our research topic. As results have shown, the following keywords have a high citation rate: Classification, Fuzzy Rule-based Classification System, Pattern Classification, Fuzzy Logic, Neural Network, ANFIS, Genetic Algorithm. From observing their time-series trends in WoS, Optimization, Diabetes, Decision Tree, Adaptive Neuro-Fuzzy Inference System (ANFIS), Big Data are popular keywords in current research with few publications. On the other hand, Fuzzy Inference System (FIS), Deep Learning, Machine Learning, Hypertension, and Big Data has a fantastic attraction to researchers in SCOPUS. Besides, clustering the relationship among these Authors Keywords is one expanded step in this research that will further free the researchers’ imagination on these Keywords. Utilizing cluster groups, we can easily extend the research focus to the remaining Keywords around a kernel Keyword.
Significantly, this research conducts four top-20 statistical parts, namely the TOP 20 SETs sub-section. It covers publications, references, resources, and conferences. But the TOP SETs will not further analyze these publications extracted from databases. The construction of the four statistical parts depends on three research goals. The first is to determine which resources will have a significant impact on the research topic and can be used as necessary resources to support our research. The second is mainly to assess the correlation between future research and high-impact resources. The third is to resolve where to obtain high-quality resources on our research topics, and where to publish our research results. Therefore, future research can utilize the expanded TOP 20 SETs to understand the research topics more systematically and in-depth.
In short to the research, relying on the proposed systematic and time-saving bibliometric statistical analysis, all relevant publications of FIS-based classifier are used to analyze bibliometric information comprehensively. Please note that when processing data collection, if a starting year is set and it is close to 2021, the analysis results will contain more recent research information. This research focus is to explore all publications of FIS-based Classifiers. The analysis findings and statistics provide relevant researchers with a panoramic view of FIS-based classifier overall research. Moreover, it points out further research directions in this field and the most relevant research fields. The proposed bibliometric approach proves that it is entirely different from the traditional literature review analysis—no need to read the publication’s content while processing the numerous publications. Its core focus is to use bibliometric information to explore one research topic. Therefore, the feature makes a boundary between traditional review analysis and bibliometric statistical analysis. In future work, we will make the bibliometric analysis method more systematic and standardized. So that the analysis method can be used in any research field to evaluate research topics quickly and reliably without worrying about the lack of collection methods or unclear topics. Simultaneously, we will explore more effective and precise formulas to analyze and model the relationship between citations and bibliometric information more profoundly and systematically. In addition, the proposed approach has a shortcoming in analyzing the Author Keywords part. Although the overall analysis results are currently robust, the impact of the skill levels of different authors on the distribution of the Keywords has not yet been determined. Besides, due to the standard of the Datasets exported from databases is insufficient when data volume is enormous, some similar resources have different expressions. Sometimes, the effect is fatal to the analysis results. Therefore, how to format them is still one crucial pre-processing work for obtaining high-quality results. It can be seen that, the further development of bibliometric statistical analysis methods is essential for the development of survey technology.
ACKNOWLEDGMENT
The authors are grateful for the reviewers’ and editors’ critical, detailed, and constructive comments, which helped to improve the paper quality significantly.
No comments:
Post a Comment