In order to improve the quality of systematic researches, various tools have been developed by well-known scientific institutes sporadically. Dr. Nader Ale Ebrahim has collected these sporadic tools under one roof in a collection named “Research Tool Box”. The toolbox contains over 720 tools so far, classified in 4 main categories: Literature-review, Writing a paper, Targeting suitable journals, as well as Enhancing visibility and impact factor.
While many researchers have heard of Digital Object Identifiers (DOIs), some may not know why and when they should be used. The
single most important characteristic of DOIs is that they can be
attached to just about any digital, online research output. If something
has a URL, ora specific location on the web, it can
be assigned a DOI. The versatility of DOIs means they can be tied to
journal articles, datasets, supplemental material and addendum; to
video, audio, streaming media, and 3D objects; to theses, dissertations,
technical reports, and visualizations. More recently, DOIs are being
assigned to pre-prints of articles, acknowledging the pre-print’s role
in some disciplines to be as valuable asthe published version.
Why does this matter? As the APA Style Blog explains,
The DOI is like a digital fingerprint: Each article
receives a unique one at birth, and it can be used to identify the
article throughout its lifespan, no matter where it goes. (https://shar.es/1VECYv)
This digital fingerprint grows in importance as we move into an era that scholar Péter
Jacsó has described as a “metadata mega mess.” Keyword searches by
title or author in Google, for example, and even Google Scholar, which
relies on mechanisms rather than unique IDs, often return inaccurate
information: titles are attributed to the wrong authors, especially
those with common names; citations of articles are mistaken for the
original article; publication years become volume numbers; and a score
of other inaccuracies. Researchers who rely on Google Scholar often quip
that the service provides an easy way to begin a citation search, but
that sources must be verified by DOI through Crossref and other
registries. An article with a DOI reduces its risk of becoming lost in
this “metadata mega mess” (Péter Jacsó, “Metadata mega mess in Google Scholar”, Online Information Review 2010: 34.1: 175-191, https://doi.org/10.1108/14684521011024191).
The second essential feature of the DOI is that it is persistent.As a unique identifier, it enables digital objects to be found anywhere, anytime with a one
simple click on a link. This means that a paper or dataset is
accessible and discoverable without requiring a separate search.
Incorporated into a citation, the DOI becomes a guaranteed location for
the item cited because it will always resolve to the right web address
(URL). When attached to a resource, the DOI is also machine-readable, supporting online discovery as well as targeted aggregations and indexes. The Anatomy of a DOI Every DOI has three parts: Source: http://www.ands.org.au/online-services/doi-service/doi-policy-statement. CC-BY
Resolving Web Address. Like web addresses (URLs),
DOIs enable research output to be discoverable and accessible. Online
publishing and digital archiving have made them almost a necessity for
scholarship, and they have become the de facto standard for identifying
research output.
Prefix. The prefix is the beginning of a unique,
alphanumeric ID that irrefutably represents a digital object, and as
such it creates an actionable, interoperable, persistent link to the
work. The prefix is almost always associated with the entity or
organization, and can allow users to trace the digital material back to
its source.
Suffix. The final part of the alphanumeric ID is
unique to its assigned object. Integrity of DOIs are guaranteed because
they do not rely alone on URLs and the web’s DNS (Domain Name System)
servers for resolution. A DOI, then, is both an online location and a
unique name and description of a specific digital object. Moreover,
while the DOI base infrastructure is a species of the Handle System, DOIs run on a managed global network dedicated to their resolution.
A recent data DOI created for a data set in the IUScholarWorks repository (https://doi.org/10.5967/K8SF2T3M)
illustrates one of our unique prefix “shoulders” (10.5967/K8) and a
randomly generated alphanumeric string that is unique to this object
(SF2T3M). Our open access journal system, on the other hand, is
configured to create DOIs that are more semantic and tell us more about
the object. This DOI (https://doi.org/10.14434/v17i3.21306)
also has a unique prefix for Indiana University’s open journal system
(10.14434). What’s more, the rest of the ID tells us that it is from
Volume 17, Issue 3, article number 21306 of its originating journal. So, Why DOI?
The short answer is that DOIs increase the reach and impact of your
work. Publishers, repositories, aggregators, indexers, and providers of
research and academic profiles are now relying on DOIs to identify
specific works accurately, which in turn more reliably links that work
to its authors and creators. Furthermore, metadata and information about
individual works are increasingly tied to DOIs.
Crossref — one of the largest providers of DOIs for publications and
the provider of DOIs for our open journal program — continues to expand
the metadata that can be tied to DOIs, thereby increasing what your work
can do in the world. The Scholarly Communication Department plans to
deploy two specific Crossref programs that use DOIs to improve the
accuracy and accessibility of usage data, bibliometrics, research
profiles, and altmetric impact. Cited-by uses an
object’s DOI to track where and how a digital publication or data has
been cited, and can be displayed alongside an article with other
metadata, such as authors’ bios (https://www.crossref.org/services/cited-by). Event Data,
a program currently being rolled out by Crossref, goes even further. It
will leverage the increasing ubiquity of DOIs to enhance the metrics
available to scholars for their work. Known commonly as altmetrics,
Event Data will collect a publication’s appearance on social media and
online communities, such as Wikipedia, Reddit, Twitter, Stack Exchange,
and blog posts (https://www.crossref.org/services/event-data).
Furthermore, for any research products — from software and datasets
to technical reports and presentations –created and authored by IU
faculty, staff, and students that do not have a previously assigned DOI,
the IUScholarWorks Repository can mint them free-of-charge for any and
all submissions.
 While many researchers have heard of Digital Object Identifiers (DOIs), some may not know why and when they should be used. The
single most important characteristic of DOIs is that they can be
attached to just about any digital, online research output. If something
has a URL, or a specific location on the web, it can
be assigned a DOI. The versatility of DOIs means they can be tied to
journal articles, datasets, supplemental material and addendum; to
video, audio, streaming media, and 3D objects; to theses, dissertations,
technical reports, and visualizations. More recently, DOIs are being
assigned to pre-prints of articles, acknowledging the pre-print’s role
in some disciplines to be as valuable as the published version.
While many researchers have heard of Digital Object Identifiers (DOIs), some may not know why and when they should be used. The
single most important characteristic of DOIs is that they can be
attached to just about any digital, online research output. If something
has a URL, or a specific location on the web, it can
be assigned a DOI. The versatility of DOIs means they can be tied to
journal articles, datasets, supplemental material and addendum; to
video, audio, streaming media, and 3D objects; to theses, dissertations,
technical reports, and visualizations. More recently, DOIs are being
assigned to pre-prints of articles, acknowledging the pre-print’s role
in some disciplines to be as valuable as the published version.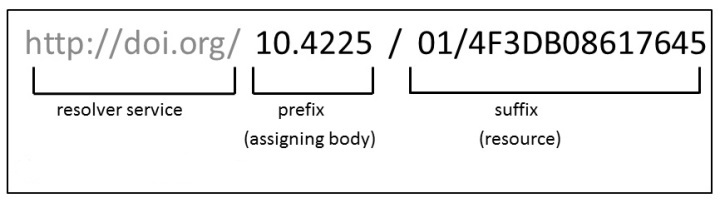
No comments:
Post a Comment