Thing 23: Altmetrics

The rise of Web 2.0 technologies is
linked to non-traditional scholarly publishing formats such as reports,
data sets, blogs, and outputs on other social media platforms. But how
do you track impact when traditional measures such as citation counts
don’t apply? Altmetrics to the rescue!
Getting Started
The term “altmetrics” (=alternative metrics) was coined in a tweet in 2010, and its development since then has gone from strength to strength, resulting in a manifesto. With no absolute definition the term can refer to- impact
measured on the basis of online activity, mined or gathered from online
tools and social media (e.g. tweets, mentions, shares, links, downloads, clicks, views, comments, ratings, followers and so on);
- metrics for alternative research outputs, for example citations to datasets;
- alternative ways of measuring research impact.
- provide a faster method of accumulation than the more traditional citation-based metrics;
- complement traditional citation-based metrics providing a more diverse range of research impact and engagement;
- offer
an opportunity to track the increasing availability of data,
presentations, software, policy documents and other research outputs in
the online environment.
Altmetric Explorer
Altmetric Explorerhas been monitoring online sources since 2012, collating data from Web
of Science, Scopus, Mendeley, Facebook, Twitter, Google+, LinkedIn,
Wikipedia (English language), YouTube, public policy documents, blogs
and more. Altmetric Explorer uses a donut graphic to visually identify the type and quantity of attention a research output has received:
The University of Melbourne Library’s subscription to Altmetric Explorer provides access to institutional data, as well as data for individual researchers and their outputs. Consider installing the Altmetric bookmarklet
on your toolbar to view Altmetric metrics for your publications. (Note:
this is only available for PubMed, arXiv or pages containing a DOI with
Google Scholar friendly citation metadata.)
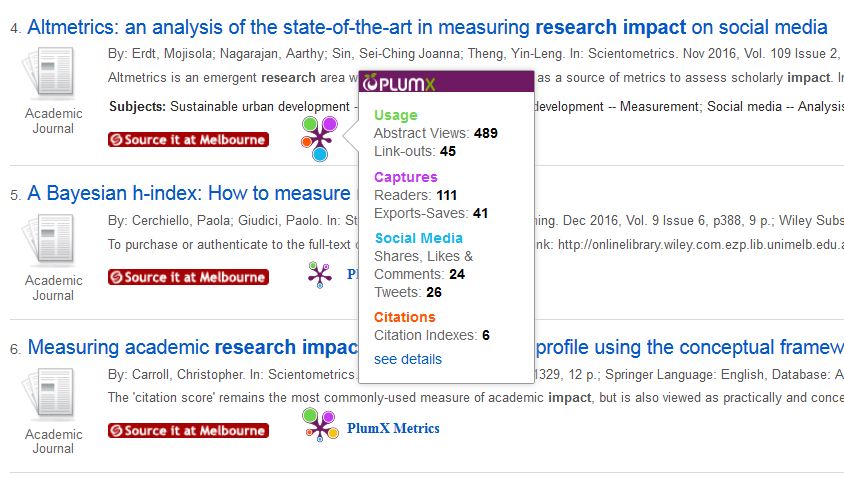
PlumX Metrics
PlumX brings together research metrics for all types of scholarly research output, categorised as follows:- Usage: clicks, downloads, views, library holdings, video plays…
- Captures: bookmarks, code forks, favorites, readers, watchers…
- Mention: blog posts, comments, reviews, Wikipedia links, news media…
- Social Media: tweets, Facebook likes, shares…
- Citations: citation indexes (CrossRef/Scopus/Pubmed Central etc), patent citations, clinical citations, policy citations…
chapters, and other resources, are available via the University of
Melbourne Library’s Discovery
search service – look for the Plum Print in the results list for your
search, and hover your cursor over it to expand details of the metrics:
Scopus
also displays PlumX Metrics for articles where available, offering an
interesting opportunity to view altmetrics alongside “traditional”
citation metrics, and the Scopus field-weighted citation impact.
Impactstory
Impactstory is anopen source, web-based researcher profile that provides altmetrics to
help researchers measure and share the impacts of their research outputs
for traditional outputs (e.g. journal articles), as well as alternative
research outputs such as blog posts, datasets and software. Researchers
can register an Impactstory profile for free via their Twitter account,
then link other profiles such as ORCID and Google Scholar, as well as Pubmed IDs, DOIs, Webpage URLs, Slideshare and Github usernames. Impactstory
then provides an overview of the attention these connected collections
have received. Information from Impactstory can be exported for private
use.
Have a look at this Impactstory example profile to find out more.
Public Library of Science – Article Level Metrics (PLOS ALMs)
If you publish research in the life sciences you can use PLOS ALMs to help guide understanding of the influence and impact of work before the accrual of academic citations.- All PLOS
journal articles display PLOS ALMs – quantifiable measures that
incorporate both academic and social metrics to document the many ways
in which both scientists and the general public engage with published
research. - PLOS ALMs are presented on the metrics tab on every published article.
- Use ALM reports to guide you to the most important and influential work published.
Minerva Access
The University of Melbourne’s institutional repository, Minerva Access,allows research higher degree students and research staff to safely
promote and self-publish their research. There are a number of
incentives for including in the repository:
- Minerva Access is harvested by Google Scholar, which in turn provides exposure and potential citation follow on
- Minerva
Access provides usage statistics for each item in the Repository as
well as each collection and sub-collection. See the left hand foot of
each page and click on the Statistics icon/link to see data on the
number of times each record has been viewed (and from which countries),
and – if applicable – the number of times any associated PDF has been
downloaded. Data is available by month and by year.
Considerations
- Altmetrics have several advantages over traditional citation counts:
they are quicker to accumulate, they document non-scholarly attention
and influence, and they can be used to track the attention for
non-traditional research outputs. However, they cannot tell anything
about the quality of the research. You need both types of metrics –
traditional and alternative – to get the full picture of research
impact. - Manual work is needed to assess the underlying qualitative data that makes up the metrics (who is saying what about research).
- While
altmetrics are good at indentifying ‘trending’ research, they have not
yet been proven to be a good indicator for lasting, long-term impact. - Researchers
seeking to evaluate non-English-language sources will find that
altmetrics coverage is currently limitied for these outputs.
Learn More
- For guidance around the tools, including useful summaries and tips, have a look at the University of Melbourne Library’s Altmetrics Subject Research Guide.
- The Altmetric Explorer website provides a range of case studies of what researchers and institutions have used to track the societal attention to their research.
- In this blog post,
Prof. Jonathan A. Eisen at the University of California, Davis,
describes how he used Impactstory to look at the altmetrics of his
research papers and data. - Dip into the readings of the PLOS Altmetrics Collection
and gather understanding on the statistical analysis of altmetrics data
sources, validation of models of scientific discovery and qualitative
research describing discovery based on altmetrics. - The London School of Economics Impact Blog regularly runs features on Altmetrics.
Thing 23: Altmetrics – 23 Research Things (2017)