Saturday, 25 March 2023
Wednesday, 22 March 2023
The top list of academic research databases
Source: https://paperpile.com/g/academic-research-databases/
The top list of academic research databases

Whether you are writing a thesis, dissertation, or research paper it is a key task to survey prior literature and research findings. More likely than not, you will be looking for trusted resources, most likely peer-reviewed research articles. Academic research databases make it easy to locate the literature you are looking for. We have compiled the top list of trusted academic resources to help you get started with your research:
1. Scopus
Scopus is one of the two big commercial, bibliographic databases that cover scholarly literature from almost any discipline. Beside searching for research articles, Scopus also provides academic journal rankings, author profiles, and an h-index calculator.
- Coverage: approx. 71 million items
- References: 1.4 billion
- Discipline: Multidisciplinary
- Access options: Limited free preview, full access by institutional subscription only
- Provider: Elsevier

2. Web of Science
Web of Science also known as Web of Knowledge is the second big bibliographic database. Usually, academic institutions provide either access to Web of Science or Scopus on their campus network for free.
- Coverage: approx. 100 million items
- References: 1.4 billion
- Discipline: Multidisciplinary
- Access options: institutional subscription only
- Provider: Clarivate (formerly Thomson Reuters)

3. PubMed
PubMed is the number one resource for anyone looking for literature in medicine or biological sciences. PubMed stores abstracts and bibliographic details of more than 30 million papers and provides full text links to the publisher sites or links to the free PDF on PubMed Central (PMC).
- Coverage: approx. 30 million items
- References: NA
- Discipline: Medicine, Biological Sciences
- Access options: free
- Provider: NIH

4. ERIC
For education sciences, ERIC is the number one destination. ERIC stands for Education Resources Information Center, and is a database that specifically hosts education-related literature.
- Coverage: approx. 1.3 million items
- References: NA
- Discipline: Education science
- Access options: free
- Provider: U.S. Department of Education

5. IEEE Xplore
IEEE Xplore is the leading academic database in the field of engineering and computer science. It's not only journal articles, but also conference papers, standards and books that can be search for.
- Coverage: approx. 5 million items
- References: NA
- Discipline: Engineering
- Access options: free
- Provider: IEEE (Institute of Electrical and Electronics Engineers)

6. ScienceDirect
ScienceDirect is the gateway to the millions of academic articles published by Elsevier. 2,500 journals and more than 40,000 e-books can be searched via a single interface.
- Coverage: approx. 16 million items
- References: NA
- Discipline: Multidisciplinary
- Access options: free
- Provider: Elsevier
7. Directory of Open Access Journals (DOAJ)
The DOAJ is very special academic database since all the articles indexed are open access and can be accessed freely of charge.
- Coverage: approx. 4.3 million items
- References: NA
- Discipline: Multidisciplinary
- Access options: free
- Provider: DOAJ

8. JSTOR
JSTOR is another great resource to find research papers. Any article published before 1924 in the United States is available for free and JSTOR also offers scholarships for independent researchers.
- Coverage: approx. 12 million items
- References: NA
- Discipline: Multidisciplinary
- Access options: free
- Provider: ITHAKA

Frequently Asked Questions about academic research databases
🗾 What is Scopus?
🌋 What is Web of Science?
🏖️ What is PubMed?
🏜️ What is ERIC?
Cite seeing: A brief guide for academics to increase their citation count
Cite seeing: A brief guide for academics to increase their citation count
Apologies to any non-academics reading my blog today but this article will be of more interest to academic researchers than anyone else as it examines the strategies that I have used to get (what some people have claimed as) an “excessive” number of citations to my published work. All academics are aware that the use of bibliometric data is becoming ever more important in academia. Along with impact factors of academic journals, one of the most important bibliometric indicators is citation counts. These are increasingly being used in a number of contexts including internal assessment (e.g., going for a job promotion) and external assessments (e.g., use in the Research Excellence Framework [REF] as a proxy measure of quality and impact).
In June 2016 I reached close to 30,000 citations on Google Scholar and this is good evidence that what I do day-to-day works. I have an h-index of 91 (i.e., at least 91 of my papers have been cited 91 times) and an i10-index of 377 (i.e., a least 377 of my papers have been cited 10 times).
Citation counts take years to accumulate but you can help boost your citations in a number of different ways. Here are my tips and strategies that I personally use and that I know work. It probably goes without saying that the more you write and publish, the greater the number of citations. However, here are my top ten tips and based on a number of review papers on the topic (see ‘Further reading’ below):
- Choose your paper’s keywords carefully: In an age of search engines and academic database searching, keywords in your publications are critical. Key words and phrases in the paper’s title and abstract are also useful for search purposes.
- Use the same name on all your papers and use ORCID: I wish someone had told me at the start of my career that name initials were important. I had no idea that there were so many academics called ‘Mark Griffiths’. Adding my middle initial (‘D’) has helped a lot. You can also use an ORCID or ResearcherID and link it to your publications.
- Make your papers as easily accessible as possible: Personally, I make good use of many different websites to upload papers and articles to (ResearchGate and academia.edu being the two most useful to me personally). Your own university institutional repositories can also be useful in this respect. All self-archiving is useful. It is also especially important to keep research pages up-to-date if you want your most recent papers to be read and cited.
- Disseminate and promote your research wherever you can: I find that many British academics do not like to publicise their work but ever since I was a PhD student I have promoted my work in as many different places as possible including conferences, seminars, workshops and the mass media. More recently I have used social media excessively (such as tweeting links to papers I’ve just published). I also write media releases for work that I think will have mass appeal and work with my university Press Office to ensure dissemination is as wide as possible. I also actively promote my work in other ways including personal dissemination (e.g., my blogs) as well as sending copies of papers to key people in my field in addition to interested stakeholder groups (policymakers, gaming industry, treatment providers, etc.). I have a high profile web presence via my many websites.
- Cite your previously published papers: Self-citation is often viewed quite negatively by some academics but it is absolutely fine to cite your own work where relevant on a new manuscript. Citing my own work has never hurt my academic career.
- Publish in journals that you know others in your field read: Although many academics aim to get in the highest impact factor journal that they can, this doesn’t always lead to the highest number of citations. For instance, when I submit a gambling paper I often submit to the Journal of Gambling Studies (Impact factor=2.75). This is because gambling is a very interdisciplinary field and many of my colleagues (who work in disparate disciplines – law, criminology, social policy, economics, sociology, etc.) don’t read psychology journals. Some of my highest cited papers have been in specialist journals.
- Try to publish in Open Access journals: Research has consistently shown that Open Access papers get higher citation rates than non-Open Access papers.
- Write review papers: Although I publish lots of empirical papers I learned very early on in my academic career that review papers are more likely to be cited. I often try to write the first review papers in particular areas as everyone then has to cite them! Some types of outputs (especially those that don’t have an abstract) are usually poorly cited (e.g., editorials, letters to editors).
- Submit to special issues of journals: Submitting a paper to a special issue of a journal increases the likelihood that others in your field will read it (as it will have more visibility). Papers won’t be cited if they are not read in the first place!
- Publish collaboratively and where possible with international teams. Again, research has consistently shown that working with others collaboratively (i.e., team-authored papers) and in an international context has been shown to significantly increase citation counts.
Finally, here are a few more nuggets of information that you should know when thinking about how to improve your citation counts.
- There is a correlation between number of citations and the impact factor of the journal but if you work in an interdisciplinary field like me, more specialist journals may lead to higher citation counts.
- The size of the paper and reference list correlates with citation counts (although this may be connected with review papers as they are generally longer and get more cited than non-review papers.
- Publish with ‘big names’ in the field. Publishing with the pioneers in your field will lead to more citations.
- Get you work on Wikipedia References cited by Wikipedia pages get cited more. In fact, write Wikipedia pages for topics in your areas.
- Somewhat bizarrely (but true) papers that ask a question in the title have lower citation rates. Titles that have colons in the title have higher citation rates.
Note: A version of this article was first published in the PsyPAG Quarterly (see below)
Dr Mark Griffiths, Professor of Behavioural Addictions, International Gaming Research Unit, Nottingham Trent University, Nottingham, UK
Further reading
Ball, P. (2011). Are scientific reputations boosted artificially? Nature, May 6. Located at: http://www.nature.com/news/2011/110506/full/news.2011.270.html (last accessed April 27, 2015).
Bornmann, L., & Daniel, H. D. (2008). What do citation counts measure? A review of studies on citing behavior. Journal of Documentation, 64(1), 45-80.
Corbyn, Z. (2010). An easy way to boost a paper’s citations. Nature, August 13. Located at: http://dx.doi.org/10.1038/news.2010.406 (last accessed April 27, 2015).
Ebrahim. N. A. (2012). Publication marketing tools – Enhancing research visibility and improving citations. University of Malaya. Kuala Lumpur, Malaysia. Available at: http://works.bepress.com/aleebrahim/64
Ebrahim, N., Salehi, H., Embi, M. A., Habibi, F., Gholizadeh, H., Motahar, S. M., & Ordi, A. (2013). Effective strategies for increasing citation frequency. International Education Studies, 6(11), 93-99.
Ebrahim, N.A., Salehi, H., Embi, M. A., Habibi, F., Gholizadeh, H., & Motahar, S. M. (2014). Visibility and citation impact. International Education Studies, 7(4), 120-125.
Griffiths, M.D. (2005). Self-citation: A practical guide. Null Hypothesis: The Journal of Unlikely Science (‘Best of’ issue), 15-16.
Griffiths, M.D. (2015). How to improve your citation count. Psy-PAG Quarterly, 96, 23-24.
Jamali, H. R., & Nikzad, M. (2011). Article title type and its relation with the number of downloads and citations. Scientometrics, 88(2), 653-661.
Marashi, S.-A., Amin, H.-N., Alishah, K., Hadi, M., Karimi, A., & Hosseinian, S. (2013). Impact of Wikipedia on citation trends. EXCLI Journal, 12, 15-19.
MacCallum, C. J., & Parthasarathy, H. (2006). Open Access increases citation rate. PLoS Biology, 4(5), e176, http://dx.doi.org/10.1371/journal.pbio.0040176
Swan, A. (2010) The Open Access citation advantage: Studies and results to date. Located at: http://eprints.soton.ac.uk/268516/ (last accessed April 27, 2015).
Vanclay, J. K. (2013). Factors affecting citation rates in environmental science. Journal of Informetrics, 7(2), 265-271.
van Wesel, M., Wyatt, S., & ten Haaf, J. (2014). What a difference a colon makes: How superficial factors influence subsequent citation. Scientometrics, 98(3): 1601–1615.
Share this:
Broadening your Research Impact
Broadening your Research Impact
Tips for Increasing Research Impact
Increase the impact of your Manuscript
- Publish where it counts - journals that are indexed by major citation services, eg Scopus help increase recognition for your work.
- Select the appropriate Journal –consider Journal Impact Factor, Scopus ASJC Codes, cross-discipline, where do your peers and competitors publish?
- Aim high - papers in highly cited journals attract more citations and sooner - Top Journals in Scopus
- Consider the publication timeline - does the journal do preprints? Digital Object Identifier?
- Title – longer more descriptive article titles attract more citations.
- Title (and Abstract) words are heavily weighted by search engines and a keyword-rich title will push your article towards the top.
- Write a clear Abstract, repeat key phrases (search engines search the Abstract)
- Write a Review - Citation rates of reviews are generally higher than other papers
- Use more references – strong relationship between no of references and citations.
- Open Access to underlying research data and materials – makes your paper very attractive Check the review period and on-line pre-prints.
- Publish in Open Access journals and Open Access Digital repository – greater access, visibility, digital access and some research funders insisting.
International Collaboration
- International experts in your field (Scival can help identify potential collaborators)
- Multi author and multi institutes
- Correlation with higher citation rates
Promotion, Visibility and Accessibility
- Importance of Self Promotion, Networking and Visibility
- Participate in conferences and meetings – present your work at every opportunity
- Offer to give lectures or talk about your research.
- Build an online presence:
Create a website that lists your publications –include University of Galway.
Use Social Media - Facebook, Twitter, ResearchGate, LinkedIn, Blogs, Youtube video, TedEd lesson etc
- Utilize both Institution and publisher press releases and public relations.
- Distribute reprints to scientists you have cited or to those who may find your work interesting.
- Publish in Open Access Journals and Open Access Digital repository – greater access, visibility, digital access and some research funders insisting.
Cite and you will be Cited
- Cite your colleagues, including those with results contrary to yours
- Cite leaders in your field and pertinent papers.
- Self Citations - Cite your own relevant work (limit to 3 or 4, only include Journal Papers)
and Finally - Make sure you get the credit for your work - see Publishing Guidelines for Researchers
- Manage your online identity – Consistent form of your name, ORCID ID
- Make sure you include University of Galway address in the correct form.
- Reclaim any misspelt citations by others – Scopus feedback service.
- Monitor your output ensuring bibliometric databases accurately capture your work.
Sources:
• Ref: Effective Strategies for Increasing Citation Frequency: http://eprints.rclis.org/20496/1/30366-105857-1-PB.pdf
• http://www.jobs.ac.uk/careers-advice/working-in-higher-education/2169/how-to-increase-your-citation-rates-in-10-easy-steps-part-1
• http://www.aje.com/en/arc/10-easy-ways-increase-your-citation-count-checklist/
How good are AI “Answering Engines” really?
Source: https://blog.kagi.com/kagi-ai-search#aitest
How good are AI “Answering Engines” really?
When implementing a feature of this nature, it is crucial to establish the level of accuracy that users can anticipate. This can be accomplished by constructing a test question dataset encompassing challenging and complex queries, typically necessitating human investigation but answerable with certainty using the web. It is important to note that AI answering engines aim to streamline the user’s experience in this realm. To that end, we have developed a dataset of ‘hard’ questions from the most challenging we could source from Natural Questions dataset, Twitter and Reddit.
The questions included in the dataset range in difficulty, starting from easy and becoming progressively more challenging. We plan to release the dataset with the next update of the test results in 6 months. Some of the questions can be answered “from memory,” but many require access to the web (we wanted a good mix). Here are a few sample questions from the dataset:
- “Easy” questions like “Who is known as the father of Texas?” - 15 / 15 AI providers got this right (all AI providers answered only four other questions).
- Trick questions like “During world cup 2022, Argentina lost to France by how many points?” - 8 / 15 AI providers were not fooled by this and got it right.
- Hard questions like “What is the name of Joe Biden’s wife’s mother?” - 5 / 15 AI providers got this right.
- Very hard questions like “Which of these compute the same
thing: Fourier Transform on real functions, Fast Fourier Transform,
Quantum Fourier Transform, Discrete Fourier Transform?” that only one provider got right. (thanks to @noop_noob for suggesting this question on Twitter.
In addition to testing Kagi AI’s capabilities, we also sought to assess the performance of every other “answering engine” available for our testing purposes. These included Bing, Neeva, You.com, Perplexity.ai, ChatGPT 3.5 and 4, Bard, Google Assistant (mobile app), Lexii.ai, Friday.page, Komo.ai, Phind.com, Poe.com, and Brave Search. It is worth noting that all providers, except for ChatGPT, have access to the internet, which enhances their ability to provide accurate answers. As Google’s Bard is not yet officially available, we opted to test the Google Assistant mobile app, considered state-of-the-art in question-answering on the web just a few months ago. Update 3 / 21: We now include Bard results.
To conduct the test, we asked each engine the same set of 56 questions and recorded whether or not the answer was provided in the response. The answered % rate reflects the number of questions correctly answered, expressed as a percentage (e.g., 75% means that 42 out of 56 questions were answered correctly).
And now the results.
| Answering engine | Questions Answered | Answered % |
|---|---|---|
| Human with a search engine [1] | 56 | 100.0% |
| ——————————- | ——————– | ———- |
| Phind | 44 | 78.6% |
| Kagi | 43 | 76.8% |
| You | 42 | 75.0% |
| Google Bard | 41 | 73.2% |
| Bing Chat | 41 | 73.2% |
| ChatGPT 4 | 41 | 73.2% |
| Perplexity | 40 | 71.4% |
| Lexii | 38 | 67.9% |
| Komo | 37 | 66.1% |
| Poe (Sage) | 37 | 66.1% |
| Friday.page | 37 | 66.1% |
| ChatGPT 3.5 | 36 | 64.3% |
| Neeva | 31 | 55.4% |
| Google Assistant (mobile app) | 27 | 48.2% |
| Brave Search | 19 | 33.9% |
[1] Test was not timed and this particular human wanted to make sure they were right
Disclaimer: Take these results with a grain of salt, as we’ve seen a lot of diversity in the style of answers and mixing of correct answers and wrong context, which made keeping the objective score challenging. The relative strength should generally hold true on any diverse set of questions.
Our findings revealed that the top-performing AI engines exhibited an accuracy rate of approximately 75% on these questions, which means that users can rely on state-of-the-art AI to answer approximately three out of four questions. When unable to answer, these engines either did not provide an answer or provided a convincing but inaccurate answer.
ChatGPT 4 has shown improvement over ChatGPT 3.5 and was close to the best answering engines, although having no internet access. This means that access to the web provided only a marginal advantage to others and that answering engines still have a lot of room to improve.
On the other hand, three providers (Neeva, Google Assistant, and Brave Search), all of which have internet access, performed worse than ChatGPT 3.5 without internet access.
Additionally, it is noteworthy that the previous state-of-the-art AI, Google Assistant, was outperformed by almost every competitor, many of which are relatively small companies. This speaks to the remarkable democratization of the ability to answer questions on the web, enabled by the recent advancements in AI.
The main limitation of the top answering engines at this time seems to be the quality of the underlying ‘zero-shot’ search results available for the verbatim queries. When humans perform the same task, they will search multiple times, adjusting the query if needed, until they are satisfied with the answer. Such an approach still needs to be implemented in any tested answering engine. In addition, the search results returned could be optimized for use in answering engines, which is currently not the case.
In general, we are catiously optimistic with Kagi’s present abilities, but we also see a lot of opportunities to improve. We plan to update the test results and release the questions in 6 months as we compare the progress made by the field.
How Q&A systems based on large language models (eg GPT4) will change things if they become the dominant search paradigm - 9 implications for libraries
Source: https://musingsaboutlibrarianship.blogspot.com/2023/03/how-q-systems-based-on-large-language.html
How Q&A systems based on large language models (eg GPT4) will change things if they become the dominant search paradigm - 9 implications for libraries
Warning : Speculative piece!
I recently did a keynote at the IATUL 2023 conference where I talked about the possible impact of large language models (LLMs) on academic libraries.
Transformer based language models whether encoder-based ones like BERT (Bidirectional Encoder Representations from Transformers) or auto-regressive decoder-based ones like GPT (Generative Pretrained Transformers) brings near human level capabilities in NLP (Natural Language Processing) and (particularly for encoder based GPT models) NLG (Natural Language Generation).
This capability can be leveraged in almost unlimited ways - as libraries can leverage capabilities like Text sentiment analysis, Text classification, Q&A, code completion, text generation for a wide variety of tasks, particularly since such LLMs are so general, they need minimal finetuning (which "realistically be used by researchers with relatively little programming experience") to get them to work well.
This article in ACRL provides a brief but hardly comprehensive series of possible uses - for example, it does not include uses such as OCR correction for digitalization work and other collections related work. Neither does it talk about copyright issues, the role libraries may play in supporting data curation and open source Large Language Models.
Yes, I don't think it takes a futurist to say that the impact of LLMs and workable Machine Learning, Deep Learning is going to be staggering.
But for this article I'm going to focus on one specific area I have some expertise in, the implications of large language models (LLMs) on information retrieval and Q&A (Question and answer tasks) where LLMs are used in search engines to extract and summarise answers from top ranked documents.
I argue this new class of search engines represent a brand-new search paradigm that will catch on and change the way we search, obtain and verify answers.
We have essentially the long promised Semantic Search over documents, where instead of the old search paradigm of showing 10 blue links to possible relevant documents, we can now extract answers directly from webpages and even journal articles, particularly Open Access papers.
What implications will this have for library services like reference and information literacy? Will this give an additional impetus to the push for Open Access? How will this new search paradigm affect relationships between content owners like Publishers and discovery and web search vendors?
1. The future of search or information retrieval is not using ChatGPT or any LLM alone but one that is combined with a search engine.
ChatGPT by OpenAI was made open to all with no waitlist in Nov 2022 and it quickly went viral.
As a result, most of the current thinking is based on the idea that the future will be ChatGPT or one of it's future versions.
Here are three general papers I know of on academic libraries impacts on ChatGPT
and this is well and good.
But while large language models will certainly be used in many of the ways described in these articles, in the long run they will not I believe be used for information retrieval, or in the library context reference services.
Instead, the future belongs to tools like the New Bing, Perplexity.ai, Google's Bard which combine search engines with Large Language Models.
Technically speaking many search engines, you use today like Google, Elicit.org might already be using Large Language Models under the hood to improve query interpretation and relevancy ranking. For example, Google already uses BERT models to better understand your search query, but this is not visible to you and is not the LLM use I am referring to. This type of search where queries and documents are converted into vector embeddings using the latest transformer-based models (BERT or GPT-type models) and are matched using something like cosine similarity is often called Semantic Search . Unlike mostly keyword based techniques they can match documents with queries that are relevant even if the keywords are very different. But at the end of the day they still revert to the two decade old paradigm of showing most relevant documents and not the answer.
See simple expexplanationhese tools work in a variety of ways but speaking, they do the following
1. User query is interpreted and searched
How this is done is not important, but more advanced systems like OpenAI's unreleased WebGPT, hooks up a LLM with a Search API and trains it to learn what keywords to use (and even whether to search!), by "training the model to copy human demonstrations" but this is not necessary, and this step could be accomplished with as simple as a standard keyword search
2. Search engine ranks top N documents
Results might be ranked using traditional search ranking algo like BM25,TF-IDF or it might be using "semantic search" using transformer based embeddings (see above). or some hybrid-multiple stage ranking system with more computational expensive methods in later stages.
3. Of the top ranked documents, it will try to find the most relevant text sentences or passages that might answer the question
Again, this usually involves using embeddings (this time at sentence level) and similarity matches to determine the most relevant passage. Given that GPT-4 has a much bigger context window, one can possibly even just use the whole page or article for this step instead of passages.
4. The most relevant text sentences or passages will then be passed over to the LLM with a prompt like "Answer the question in view of the following text".
Why is this better for information retrieval than just using a LLM like ChatGPT alone?
There are two reasons.
Firstly, it is known that LLMs like ChatGPT may "hallucinate" or make things up. One way to counter this is to ask it to give references.
Unfortunately, it is well known by now ChatGPT tends to make references up as well! Depends on your luck you may get references that are mostly real , but most likely you will get mostly fake references.

In the example above, all three references are fake. Interestingly a lot of them are pretty pausible.
The authors are wrong though, but the authors are plausible, e.g. Anne-Wil Harzing (of software Hazing Publish or Perish Software) does publish papers on size of Google Scholar vs Scopus but has not to my knowledge published papers that directly estimate size of Google Scholar etc. This is the actual paper that does answer the question in PLOSONE by Madian Khabsa and C. Lee Giles published in 2014.
There's a similar pattern for the second paper included - the actual paper is here but the author is different.
My
non-scientific way of thinking about this is like if you asked a human
with his memory alone unaided with tools to cite papers, he most likely
would get things wrong. But what happens if he could search and "look
through" top results and cite those documents?
This is what the new Bing and Perplexity.ai does. (See also academic versions like Elicit.org, Scite.ai's ask a question, Consensus etc).
Let's try the same question again .
Here's the same search for perplexity.ai.

Notice it cites papers or at least URLs
The same applies for the new Bing,

Both Bing and Perplexity use OpenAI's GPT models via APIs and as such work similarly.
Perplexity even shows the sentence passage used to help generate the answer

Compare ChatGPT to these search engines. Because these new search engines link to actual papers or webpages it doesn't ever makeup references by definition. It can still "misinterprete" the citations of course.
For example, I've found such systems may confuse the findings of other papers mentioned in the literature review portion with what the paper actually found.
Still, this seems better than having no references for checking or fake references that don't exist.
As I write this GPT-4 was released and it seems to generate a lot less fake references. This is quite impressive since it is not using search.
Secondly, even if LLMs used alone without search can generate mostly real citations, I still wouldn't use it for information retrieval.
Consider a common question - that you might ask the system. What are the opening hours of <insert library>.

ChatGPT got the answer wrong. But more importantly without real-time access to the actual webpage, even if it was right the best it can do is to reproduce the website it saw during training and this could be months ago!
Retraining LLMs completely is extremely expensive and as such the data it is trained is always going to be months behind. Even if you simply finetune the full model and not retrain it from the scratch it will still not update as quickly as a real time search.
Adding search to a LLM solves the issue trivially, as it could find the page with the information and extract the answer.
Technically speaking these systems will match documents based on the cached copy the search engine sees, so this can be hours or days out of date. But my tests shows they will actually scrape the live page of these documents for answers, so the answers are based on real-time or at least the information on the page at the time of the user query.

I did notice that Bing+Chat works similarly to ChatGPT and GPT in that it's answers are not deterministic, ie there is some randomness to the answers (technically this is adjusted via a "temperature" variable via the API and is technically set to 0.7, 0 = no randomness)
In fact, most of the time it gets the answer wrong. My suspicion is it's confused by tables.....
2. Search+LLM will catch on quickly even if it is initially not very accurate
As I write this, most people are still not familiar with search enhanced with LLMs. But with Microsoft lifting the waitlist now on the new Bing+chat things might change very quickly.
My
prediction is that these new search tools, including Google's soon to
be released Bard, will gain popularity very quickly and going forward
this new search paradigm will become the default.
Why? Simple. Convenience!
Google
and Web search engines were a great advancement to information
retrieval. You entered a keyword, scanned the top few results, which
hopefully had the answer you wanted.
This new
advancement goes even further. You no longer even have to scan the
documents for results. The system scans and extracts the answer for
you!

This was always the limiting factor of traditional search engines.
As
a librarian, one article of faith I was told is users don't read FAQs.
Google Search helped because users could be dropped on those FAQs with
the answers but I still find many questions from users via our chat
services that can trivally be answered by a google search and reading
the information on the top ranked page.
Occasionally, Google would extract answers and display them - via “featured snippet” , see the example below about opening hours, but this was the exception not the rule.

With the new class of search engines this would be the norm for every search not just selected ones!
Of
course, the reason why people still ask questions that can be found on a
webpage is that sometimes the user would even be on the page or
document with the answer but would be daunted due to the length of the
document/page or the jargon used. This is certainly true for academic
works!
These new systems bypass all these issues.
Of
course, these systems are not without issues. The main one off the bat
is that even though they may refer to real articles or pages, they may
extract or summarise the answers wrongly. How accurate are these
systems? I am unaware of any study on this issue, but I have heard that
Elicit.org (an academic system searching only academic papers using
Semantic Scholar but using similar LLMs) is around 70% accurate at
extracting information.
I know librarians and
educators are going to say 70% isn't good enough and maybe it isn't. But
this technology is going to improve and the irony is the better it
becomes, the more people will not bother to check the citations.
But
if I were to guess , based on the history of librarianship and ideas
from books like the Innovator's dilemma this technology is going to win
out.
Convenience is king. Web search engines
when first introduced weren't very good, and did not give as reliable
answers as printed books, but despite that they were preferred by
everyone and today the main way to learn things is via web search.
The
same story repeated with Google Scholar. It wasn't very good when first
introduced, didn't have a large coverage of most journals, had (and
still does) inferior search and browse features than our traditional
databases and yet again the convenience of searching large numbers of
articles reliably and quickly (something federated search engines of the
day could not do) instead of using individual databases won out again.
Today most researchers start at Google Scholar.
3. Decent chat bots for libraries are practical now
Like many industries, Libraries have tried to create chatbots. I have never been impressed with them, they were either simple minded "Select from limited x options" systems that hardly deserved the name bot, or extremely hard to train systems that you would need to specially train for individual questions and would do well only for a very small, limited set of questions.
I believe chatbots are now practical. In the earlier part of my career, I spent time thinking about and implementing chat services for libraries. In general chat services questions relate to the following major classes of questions
1. Queries about details of library services
2. APA questions
3. General Research Questions.
Another category of questions are troubleshooting questions which I did not test. This depends mostly on how good your faqs are on this class of questions. But I have not tried how it reacts to error messages being relayed to it,
Using just the new Bing+Chat which was not optimized for the library chatbot use case, the results are amazing.
I start off asking Bing about opening hours of my library.

It knows I'm from Singapore and it correctly points out it depends on which library I am talking about.

Notice
how it doesn't just answer the question, but also acts very much like a
librarian, asking followup questions like "what else I would like to
know about the library". There's also a list of options at the bottom
you can follow up with.
Next, I try yet another basic question on borrowing privileges.

Again, it finds the right page but misinterprets the table on the page.
Of course, you might think, this isn't a big deal, your library bot can answer this and correctly too. But the difference is here we have a bot that isn't specifically trained at all! All it did was read your webpage and it found the answers. It even has a conversational, librarian-like demeanor!
I know from past tests, chatGPT is pretty good at APA citing, if you give it the right information.
I was curious to see given that Bing+GPT can actually "see" the page you are referring to, it might be able to give you the right citation when you pass it a URL.

The results are disappointing. It is unable to spot the author of the piece. Even when I prompted it to summarise the URL which triggered it to search and "See" the page, when I asked it for APA 7th it couldn't spot the author. But of course when I supplied the author it took that into account.
In general, while it is possible with some work to anticipate the majority of non-research questions and train the bot for it, research questions can be pretty much anything under the sun and is impossible to anticipate.
So it was the performance on the third class of question, research questions that shocked me.
In my last blog post, I talked about how it could be used to find seminal works and even compare and constrast works.

One common question we get via chat service is dataset questions


Trying
the same query in Perplexity but limiting it to results from
smu.edu.sg, gets even better and more specific answers, because it can
"see" into the Open Access PDF, available on our institutional
repository and from there it can figure out the right datasets/databases
typically used by our researchers! More on that later.

Btw this barely scratches the surface on what these new search systems can do for research questions (see also later).









 The
significant of all this is you can now do Question and Answering over
full-text of papers, particularly if they are Open Access!
The
significant of all this is you can now do Question and Answering over
full-text of papers, particularly if they are Open Access!
4. Reference desk and general chat usage will continue to decline
Reference desk queries have been falling for over a decade. Mostly due to the impact of Google and search engines. These new class of search engines may be the final nail in the coffin.
Don't get me wrong, this does not mean - Reference is dead, it just means the general reference desk or even general chat will be in further decline.
The problem with the general reference query is this. Even if you are the most capable reference librarian in the world, there is no way you can know or be familiar with every subject under the sun.
The nature of general reference is that when a question is asked, unless it is a question or topic you are somewhat familiar already (unlikely if you are in a University that spans many disciplines), if you try to answer the question (and you usually do as a stop gap), you will typically be googling and skimming frantically to find something that might somewhat help before you pass it on to a specialist who might have a better chance of helping.
But with this new search tool, it is doing what you are doing but faster! Look at the query below.




It was basically looking at the appropriate webpages for answers and is the penultimate answer it was still smart enough to suggest alternative sources and when I asked how to do it in Bloomberg it even gave me the command directly.
And more amusingly, the answer came from a FAQ written by my librarian colleague. I would have found same but nowhere has fast.
Of course, for in-depth research queries, a specialist in the area would probably outdo the new Bing, as the answers to questions asked tends to require nuanced understanding beyond current chatbots.
That is why it is well known the toughest, "highest tier" research questions go directly to specialists not via general reference or chat.
For example, some of the toughest questions I get relate to very detailed questions on bibliometrics, search functionality etc that I get direct from faculty who are aware of my expertise. These are unlikely to be affected.
But asking such questions to a random library staff at general reference or chat is futile, because the chance it reaches someone who has a realistic chance of answering the specific research question is extremely low. In such a case, the average librarian isn't likely to outperform the new Bing.
5. Information needs to be discoverable even more (in Bing!) and a possible new Open Citation Advantage?
When I first tried Bing as a makeshift chatbot. I tried asking it another common question - access to resources.
It
naturally could tell what databases we had access to (A-Z lists are
open), but it struggled to figure out what books we had. The obvious
reason is for us, our catalog records are not indexed in Bing (but they
are in Google).
In the example below, it did
not realize my University did have access to the book "The book of why".
Even so, I was impressed by how it didn't stop there, but pointed out
you could "Suggest SMU Libraries to purchase through their website" and
if you asked it do so, it would point you to the form.

Just
to show you that it CAN find records if it is indexed, I asked it about
the National Library Board and it could find the overdrive record.

It
is well known fact that if something is not indexed by the major search
engines such as Google etc it is effectively invisible. With this class
of new search engines, this becomes even more important because your
webpage or information needs to be indexed to be founded and found for
its information to be extracted and displayed!
And
this doesn't just apply to webpages but also scholarly content like
journal articles in pdf that are indexed by the search engines.
If
you ask the new Bing, who coined the term bronze OA, it is able to come
up with the answer, but the source it obtained the result from is not
an academic paper.

If
you only want the result to come from papers, you can prompt it
accordingly and ask it to restrict results only to peer reviewed papers.
By the way, asking it to filter to specific domains works too.

Indeed, when you do it, it points to an open access paper indexed and stored on https://core.ac.uk/download/pdf/195384497.pdf .
The
answer here btw isn't quite correct. Most people do give credit to
Piwowar but the paper was published in either 2017 or 2018 (depending on
which version preprint or published version) but it wasn't from 2013!
Looking at the full-text of the citation we see this section.

Bing
appears to be crediting Piwowar but in the reference for this is the
2018 published version, but I notice the reference for [9] says "[cited
2018 Dec 13]", which is where the 2013 comes from. So it's
misinterpreting the paper.
This also shows a
slight issue for Bing, in that while it shows the document it extracts
the answer from, we are not told explicitly which exact passage of text
it used (in the above example, I had to skim the paper)
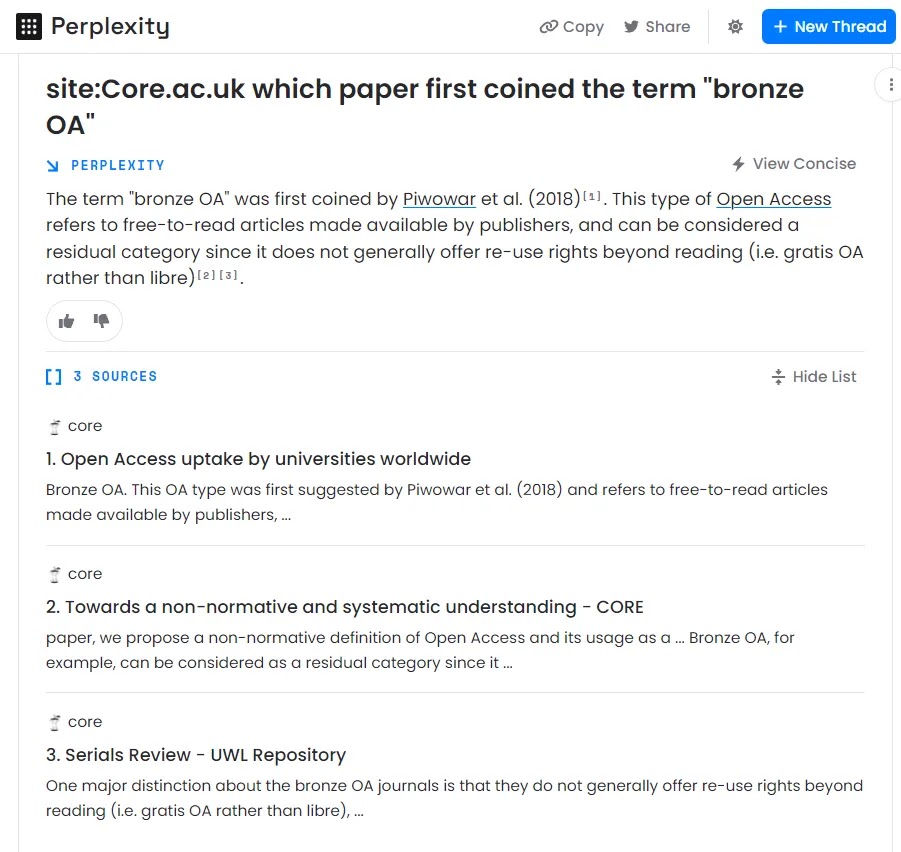
When
you do the same search In Perplexity and ask it to search within
site:Core.ac.uk only, you get not just the reference [1] but you can
even see the sentence that it used to generate the answer, so this is
even more useful for helping to validate answers.
You can either use an academic search engine that works like Bing except searching over academic text - I recommend Elicit.org, though others like Scispace, Scite's ask a question feature are all coming up.

Elicit and scite's "Ask a question" feature in particular like Perplexity, do show you the sentences it uses to generate answer.

Elicit answers and the highlight text that was used to generate answer
Or
you can use a general web search engine like Bing or Perplexity and ask
the results to be restricted to peer reviewed papers or specify a
domain where the answers come from.
A particularly useful domain to use is https://core.ac.uk/ as
it is one of the largest aggregator of Open Access content. They not
only aggregate metadata but also harvest and store copies on their
domain, so restricting to just one domain gets your answers over one of
the largest sources of Open Access.

https://core.ac.uk/
In fact, the logic of using Open Access papers in such a way is so obvious, CORE just announced CORE-GPT which allows "Combining Open Access research and AI for credible, trustworthy question answering"
What
are the implications of doing large scale question and answer over
academic papers? Firstly, open access papers are definitely going to be
the first to benefit from this as the examples above here.
While the existence of the open access citation advantage is controversial ,
it seems to me this new development might strengthen this effect. After
all, while it is true that Open Access papers are more accessible than
paywalled articles, in today's world, both are equally likely to be
discoverable via indexes like Google Scholar. Particularly for
researchers in the global north, the issue isn't paywalls but time to
read papers.
These new search terms that
extract answers directly from Open Access Papers will give OA a leg up
because there is no or less need to read the papers! If you ask a
question with such tools and one paper is Open Access and one isn't, the
former is more likely to surface since the latter's full-text probably
isn't available for extraction of answers.
Further
down the line it is interesting to speculate how this new search
paradigm will affect relationships between Content owners like Elsevier
and Google Scholar.
Just as Google is faced
with a business model issue as the nature of this new search engines
means, answers can be displayed automatically in the search without
users needing to go on to the webpages, Google Scholar and Publishers
like Elsevier will face a tricky decision.

Under
the current search paradigm, publishers of paywall content like
Elsevier, Springer-Nature allow Google Scholar to indexed the full-text
of their content including paywall articles. The logic is that this
makes their content more discoverable to readers and the readers still
need to pay to access the full-text.
The new
search paradigm where the search engine can extract and summarise
answers directly from papers upsets everything. Assuming Google Scholar
or Google Books introduces similar technology, I can always ask the
system to summarise the findings of papers (even paywalled ones) and
there is little need to read the full-text!
Assuming
publishers of paywall content stop "giving away" full-text to be
indexed by Google Scholar, what business model would they adopt? They
could always introduce the same tech for users on their platform (this
is a no-brainer) but this would only cover a subset of all the papers in
the world. Would they offer special subscription models for people who
want to integrate their LLMs with subsets of data?
6. There will be huge information literacy implications beyond warning about fake references

When
ChatGPT was first released, there was panic over the possibility of
students using it to generate essays and later people noticed the
references were mostly fake. We are even seeing reports in the wild of
naive users of ChatGPT asking to find such fake references.
This
was comforting to many who seized on this as evidence you can never use
LLMs to write essays, but I am afraid this illusion is slowly being
washed away as tools like the new Bing, Perplexity, Elicit.org become
more well known.
Still if I were a librarian
specializing in information literacy, I would be excited because I see a
ton of interesting problems and work ahead.
The first obvious thing is LLMs make it far easier to generate disinformation.

The CSET report using GPT3 to test how easy it was to automate generation of disinformation, and as a test I tried some of the techniques in my own local (Singapore context) and I was shocked at the results.
In
fact, between generative AI for text like GPT models and generative AI
for images and videos, we are entering a world where seeing and hearing
isn't believing, since the difficulty of creating fake images, and
videos is becoming almost non-existent.
But let's focus on the main theme of this blog post, a new search paradigm where search engines not just rank and display documents but also extract answers and displays them. What information literacy implications are there?
It has been suggested that "prompt engineering" or coming up with prompts to produce better results is essentially information literacy. I'm not too sure if this makes sense, since the whole point of NLP (natural language processing) is you can ask questions in nature language and still get good answers.
More fundamentally, users need to be taught how such search technologies are different from the standard "search and show 10 blue links" paradigm which has dominated for over 20 years.
How do the standard methods we teach like CRAAP or SIFT change if such search tools are used? Should we try to triangulate answers from multiple search engines like Bing vs Google Bard vs Perplexity etc?
7. Ranking of search engine results become even more important
Conventional
wisdom suggests users only look at the first page of results, perhaps
the second page. I suspect this new search paradigm where the search
engine extracts answers directly from top results might worsen this
effect.
Under the old system, you would browse,
skim through results until you got a relevant answers perhaps. As you
skim you may get some context from reading the page and you may
consciously or subconsciously notice cues of trustworthiness or
suspicion.
Extracting the answer directly from
pages removes all context. All you see if an extracted answer and a
link to a URL which to most people tells them nothing.
There's also a practical issue here. In the old search paradigm, you can easier press next page for more answers. How do you do it for the new Bing? I've found sometimes you can type "show me more" and it does get answers from lower ranked pages but this isn't intuitive.
All in all, it seems even more important for such systems to rank results well. But how should they do it?

In OpenAI's unreleased WebGPT, they hooked up a GPT model with Bing API and it was trained to know how to search in response to queries and when and what results to extract. They ran into a problem that every information literacy librarian is aware of.. how to rate the trustworthiness of sources!
Should librarians "teach" LLMs like GPT how to assess quality of webpages? The OpenAI team even hint at this by suggesting the need for "Cross-disciplinary research ... to develop criteria that are both practical and epistemically sound".
In the short run though, I hope such systems allow us to create list of whitelist and blacklist of domains to include or exclude results.
8. Long term use of such tools might lead to superficial learning.
Google
and web search engines made it possible to get quick answers and may
have led to overconfidence in estimating one's expertise in an area. I
would argue that this new search paradigm of directly extracting answers
is going to make this trend worse.
At
least with Google and web search, you had to skim through documents for
answers, and it was much slower to get answers. With this new search
paradigm, you don't even need to skim, the answers just appear. It might
become even easier to fool oneself that one is an expert...
I
was speaking to some students recently on their use of ChatGPT and they
proudly told me, they don't use it to generate essays for fear of being
caught, instead they use it to summaries long readings. I was told who
has time to read some many pages?
While there has been quite a lot of hysteria
in the educational sector over plagiarism, my view is this actually
isn't the greatest threat to education. But when people start to take
shortcuts and ask these systems to summarise long readings, alarm bells
start to sound in my head.
Even
if we grant these summaries are accurate, at the end of the day they
are just summaries. I do not believe reading a 5 point summary of a book
or an article is going to capture every nuance of the work but it may
be enough to get away with say a test.
But
in the long run are we just educating students to have superficial
understanding of things based on short summaries? How accurate are their
internal models of things if it is all based on short summaries? As I
argue in my next point, the future will need specialists with deep
expertise while generalist with superficial knowledge that such search
engines are able to generate from webpages are likely to become less
important.
9. Relative Importance of deep expertise increases
I was recently writing an article for work on the CRediT taxonomy and it took me around 30 minutes to write it all out. I later realized I could have just use ChatGPT or even better the new Bing and it would generate perfectly serviceable writings.

It wasn't better than what I wrote mind you. Just much faster. On hindsight, I probably should have realized that there are tons of pages written on the CRediT taxonomy on the web and these systems can of course generate good writings on the topic. I could add some value by customizing it to give local examples and make some particular points but otherwise I should have started with auto-generating the text on the standard parts.
The lesson to take is this, if all your knowledge is something that is so general, the answer can be found on webpages, you are probably in trouble....
For example, when I was writing the blog post on techniques for finding seminal papers, I checked with perplexity, ChatGPT to see if there were any interesting techniques but the best it could do is to state obvious answers and not the fairly novel idea I had in mind of using Q&A systems.
After I wrote up my blog post, I used Bing to ask the same question. It's first answer was roughly the same, but when I asked it to show more methods it eventually found my newly posted blog post!
The point of this story is that it shows how important it is to have deep or at least unusual expertise with ideas or points that aren't available on the web. Of course, the moment you blog or capture it in the web, it can now be found and exploited!
But if everyone is using these new tools to extract or summarise answers, how will they gain the deep expertise to provide new insights and ideas? Someone has to come up with these ideas in the first place!
Conclusion
I'm poor at conclusions, so I will let GPT-4 have the last word.

Subscribe to:
Posts (Atom)
Add a comment